JNode handbook
This book contains all JNode documentation.
Goals
JNode is a Java New Operating System Design Effort.
The goal is to create an easy to use and install Java operating system for personal use. Any java application should run on it, fast & secure!
User guide
General user information.
History
Already very early in the Java history, around JDK 1.0.2, Ewout Prangsma (the founder of JNode) dreamed of building a Java Virtual Machine in Java.
It should be a system that was not only a VM, but a complete runtime environment that does not need any other form of operating system. So is had to be a light weight and most important flexibel system.
Ewout made various attempts in achieving these goals, starting with JBS; the Java Bootable System. It became a somewhat functional system, but had far too much native code (C and assembler) in it. So he started working on a new JBS system, called JBS2 and finally JNode. It had with a simple target, using NO C code and only a little bit of assembly code.
In may on 2003 Ewout came public with JNode and development proceeded ever faster from that point on.
Several versions have been released and there are now concrete plans for the first major version.
Application testing list
This page lists java applications that we use to test JNode.
- (Should) work
- Partially usable
- Starts but doesn't really work yet
- empty
- Needs work
- Needs (lots of) work
- Not tested yet
Applications starting with A
Here is details about applications whose name starts with A
- Ant
website : http://ant.apache.org/
comments :
Applications starting with B
Here is details about applications whose name starts with B
- Beanshell
website : http://www.beanshell.org/
comments :
Applications starting with E
Here is details about applications whose name starts with E
- ecj (eclipse compiler for java)
website : http://www.eclipse.org ???
comments :
Applications starting with H
Here is details about applications whose name starts with H
- hsqldb
website : http://hsqldb.org/
comments :
Applications starting with J
Here is details about applications whose name starts with J
- JUnit
- javac
- Run "gc".
- Run "javac" with no arguments.
- Run "gc" again.
- Use "javac" to compile a (small) program.
- Jetty6
- JEdit
- JChatIRC
website : http://junit.org/
comments : only tested in console mode.
website : http://openjdk.java.net/
comments : the sun compiler for java. It works fine, but you can run into GC bugs when you compile your first program. The following "warm-up" sequence avoids this:
website : http://www.mortbay.org/
comments : it works partially
website : http://www.jedit.org/
comments : by using jedit.jar alone, I only see the splash screen. If I try the installer, it fails at 0% of progress with an "IOException" dialog box but no stacktrace.
website : http://jchatirc.sourceforge.net/
comments :
Applications starting with N
Here is details about applications whose name starts with N
- NanoHttpd
website : http://elonen.iki.fi/code/nanohttpd/
comments :
Applications starting with R
Here is details about applications whose name starts with R
- Rhino
website : http://www.mozilla.org/rhino/
comments :
Applications starting with T
Here is details about applications whose name starts with T
- tomcat
website : http://tomcat.apache.org/
comments :
Getting Started
To start using JNode you have two options:
Getting the latest released CD-ROM image
- Download the bootable CDROM image from here.
- Unzip it
- Burn it to CD-ROM
- Boot a test PC from it or start in in VMWare
Getting the latest sources and building them
- Checkout the jnode module from GitHub. See the GitHub jnode repository page for details.
- Build JNode using the build.bat (on windows) or build.sh (on unix) script.
Without parameters, these scripts will give all build options. You probably want to use the cd-x86 option that builds the CD-ROM image. - Boot a test PC from it or start in in VMWare
Getting nightly builds
- Download the nightly-builds
- You can also get the sources and a ready-to-use vmx file for VMWare
Running JNode
Once JNode has booted, you will see a JNode > command prompt. See the shell reference for available commands.
The 20 minute guided tour.
This is a quick guide to get started with JNode. It will help you to download a JNode boot image, and explain how to use it. It also will give you get you started with exploring JNode's capabilities and give you some tips on how to use the JNode user interfaces.
To start with, you need to download a JNode boot image. Go to this page and click on the link for the latest version. This will take you to a page with the downloadable files for the version. The page also has a link to a page listing the JNode hardware requirements.
At this point, you have two choices. You can create a bootable CD ROM and then run JNode on real hardware by booting your PC from the CD ROM drive. Alternatively, you can run JNode on virtual PC using VMWare.
To run JNode on real hardware:
- Download the "gzip compressed ISO image" from the JNode download page.
- Uncompress the ISO image using "gunzip".
- Use your favorite CD burning software to burn the ISO image onto a blank CD ROM.
- Shutdown your PC.
- Put the JNode boot CD into the CD drive
- Boot from the CD, following the PC manufacturer's instructions.
To run JNode from VMWare:
- Download a free copy of VMware-Player. (You can also use the free VMware-Server which allows to modify the VM parameters and so on, or you buy one of the more advanced VMWare products.)
- Install VMWare following the instructions provided.
- Download the "gzip compressed ISO image" and the "vmx" file from the JNode download page.
- Uncompress the ISO image using "gunzip", and make sure that the image is in the same directory as the "vmx" file.
- Launch VMWare, browse to find the JNode "vmx" file, and launch it as described in the VMWare user guide.
When you start up JNode, the first thing you will see after the BIOS messages is the Grub bootloader menu allowing you to select between various JNode configurations. If you have at 500MB or more of RAM (or 500MB assigned to the VM if you are using VMware), we recommend the "JNode (all plugins)" configuration. This allows you to run the GUI. Otherwise, we recommend the "JNode (default)" or "JNode (minimal shell)" configurations. (For more information on the available JNode configurations, ...).
Assuming that you choose one of the recommended configurations, JNode will go through the bootstrap sequence, and start up a text console running a command shell, allowing you to issue commands. The initial command will look like this:
JNode />
Try a couple of commands to get you started:
JNode /> dir
will list the JNode root directory,
JNode /> alias
will list the commands available to you, and
JNode /> help <command>
will show you a command's online help and usage informatiom.
There are a few more useful things to see:
- Entering ALT+F7 (press the ALT and F7 keys at the same time) will switch to the logger console. Entering ALT+F1 switches you back to the shell console.
- Entering SHIFT+UP-ARROW and SHIFT+DOWN-ARROW scroll the current console backwards and forwards.
- Entering TAB performs command name and argument completion.
- Entering UP-ARROW and DOWN-ARROW allows you to choose commands from the command history.
The JNode completion mechanism is more sophisticated than the analogs in typical Linux and Windows shells. In addition to performing command name and file name completion, it can do completion of command options and context sensitive argument completion. For example, if you want to set up your network card using the "dhcp" command, you don't need to go hunting for the name of the JNode network device. Instead, enter the following:
JNode /> dhcp eth<TAB>
The completer will show a list of known ethernet devices allowing you to select the appropriate one. In this case, there is typically one name only, so this will be added to the command string.
For more information on using the shell, please refer to the JNode Shell page,
I bet you are bored with text consoles by now, and you are eager to see the JNode GUI. You can start it as follows:
JNode /> gc
JNode /> startawt
The GUI is intended to be intuitive, so give it a go. It currently includes a "Text Console" app for entering commands, and a couple of games. If you have problems with the GUI, ALT+F12 should kill the GUI and drop you back to the text console.
By the way, you can switch the font rendering method used by the GUI before you run "startawt", as follows:
JNode /> set jnode.font.renderer ttf|bdf
If you have questions or you just want to talk to us, please consider joining our IRC channel (#JNode.org@irc.oftc.net). We're all very friendly and try to help everyone *g*
If you find a bug, we would really appreciate you posting a bug report via our bug tracker. You can also enter support and feature requests there.
Feel free to continue trying out JNode. If you have the time and the skills, please consider joining us to make it better.
Booting from the network
2 options are available here
Network boot disk
If you do not have a bootable network card, you can create a network boot disk instead. See the GRUB manual for details, or use ROM-o-matic or the GRUB network boot-disk creator.
NIC-based network boot
To boot JNode from the network, you will need a bootable network card, a DHCP/BOOTP and TFTP server setup.
- Set the TFTP base directory to <JNode dir>/all/build/x86/netboot
- Set the boot file to nbgrub-<card> where <card> is the card you are using
- Set DHCP option 150 to (nd)/menu-nb.lst
Booting from USB memory stick
This guide shows you how to boot JNode from an USB memory stick.
You'll need a Windows machine to build on and a clean USB memory stick (it may be wiped!).
Step 1: Build a JNode iso image (e.g. build cd-x86-lite)
Step 2: Download XBoot.
Step 3: Run XBoot with Administrator rights
Step 4: Open file: select the ISO created in step 1. Choose "Add grub4dos using iso emulation".
Step 5: Click "Create USB"
XBoot will now install a bootloader (choose the default) and prepare the USB memory stick.
After then, eject the memory stick and give it a try.
When it boots, you'll first have to choose JNode from the menu. Then the familiar JNode Grub boot menu appears.
Eclipse Howto
This chapter explains how to use the Eclipse 3.2 IDE with JNode.
Starting
JNode contains several Eclipse projects within a single SVN module. To checkout and import these projects into Eclipse, execute the following steps:
- Checkout the jnode module from SVN using any SVN tool you like.
Look at the sourceforge SVN page for more details. - Start Eclipse
- Select File - Import. You wil get this screen.
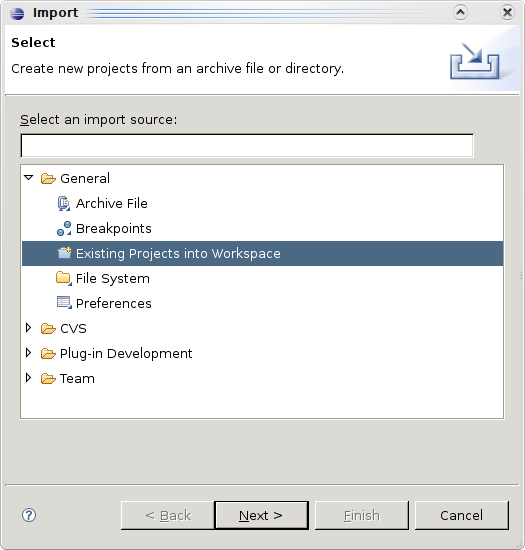
- Select "Existing project into workspace".
- Enter the root directory of the imported jnode CVS module in this screen.

The listed projects will appear when the root directory has been selected.
- Select Finish
- You will end up with all projects into your Eclipse workspace like this:

Building
You can build JNode within Eclipse by using the build.xml Ant file found in the JNode-All project. However, due to the memory requirements of the build process, it is better to run the build from the commandline using build.bat (on windows) or build.sh (on unix).
Running in Bochs
Running JNode in Bochs does not seem to work out of the box yet. It fails on setting CPU register CR4 into 4Mb paging mode.
A compile setting that enables 4Mb pages is known to solve this problem. To enable this settings, running configure with the --enable-4meg-pages argument or add #define BX_SUPPORT_4MEG_PAGES 1 to config.h.
Running in KVM
Setup
If you have a CPU with hardware virtualization support you can run JNode in kvm wich is much faster than vmware-[player|server] (at least for me). You need a CPU that either supports Intel's IVT (aka Vanderpool) or AMD's AMD-V (aka Pacifica).
With
egrep '^flags.*(vmx|svm)' /proc/cpuinfo"
you can easily check if your CPU supports VT or not. If you receive output your CPU is supported, else it is not. If your CPU is supported also check that VT is enabled in your system bios.
Load the kvm modules matching your CPU, either "modprobe kvm_intel" or "modprobe kvm_amd", install kvm user tools and setup permissions so users may run kvm (Have a look at a HOWTO for your distro for details: Ubuntu, Gentoo).
Once you have setup everything you can start kvm from the commandline (I think there are GUI frontends too, but I'm using the command line). You should be carefull though, acpi in JNode seems to kill kvm, so allways disable acpi. I also had to deactivate the kvm-irqchip as it trashed JNode. The command that works for me is:
kvm -m 768 -cdrom jnode-x86-lite.iso -no-acpi -no-kvm-irqchip -serial stdout -net none -std-vga
The "-serial" switch is optional but I need it for kdb (kernel debugger). If you want to use the Vesa mode of JNode you should also use "-std-vga", overwise you will not have a vesa mode. Set the memory whatever you like (768MB is my default).
Things that still need to be tested:

Running in parallels
I found an only way to run JNode with parallels.
In Options->Emulation flags, there is a parameter called Acceleration level that takes 3 values :
- disabled : JNode will work but that's very slow
- normal : JNode won't boot (freeze at "Detected 1 processor")
- high : JNode won't boot (freeze at "Detected 1 processor")
Running in VBox
You can now run JNode on virtual box too. ACPI is not working but you'll get a prompt and can use JNode.
TODO: Test network, usb,...
Running in Virtual PC
This page will discripe how to run JNode in Virtual PC
At the current state JNode doesn't run in Virtual PC.
Running in VMWare
Basic Procedure
The JNode build process creates a VMWare compatible ".vmx" file that allows you to run JNode using recent releases of VMWare Player.
Assuming that you build JNode using the "cd-x86-lite" target, the build will create an ISO format CDROM image called "jnode-x86-lite.iso" in the "all/build/cdroms/" directory. In the same directory, the build also generates a file called "jnode-x86-lite.iso.vmx" for use with VMWare. To boot JNode from this ".iso" file, simply run the player as follows:
$ vmplayer all/build/cdroms/jnode-x86-lite.iso.vmx
Altering the VMWare virtual machine configuration
By default, the generated ".vmx" file configures a virtual machine with a virtual CDROM for the ISO, a bridged virtual ethernet and a virtual serial port that is connected to a "debugger.txt" file. If you want to configure the VMWare virtual machine differently, the simplest option is to buy VMWare Workstation and use its graphical interfaces to configure and run JNode. (Copy the generated ".vmx" file to a different location, and use that as the starting point.)
If you don't want to pay for VMWare Workstation, you can achieve the same effect by changing the ".vmx" file by hand. However, changes you make that way will be clobbered next time you run the "build" script. The solution is to do the following:
This procedure assumes some changes in a patch that is waiting to be committed.
- Create a file containing the VMX properties that you want to add or replace. Put this file somewhere that won't be clobbered by "build clean".
- Copy the "jnode.properties.dist" file to "jnode.properties".
- Open the "jnode.properies" file in a text editor.
- Find the line that starts "#vmware.vmx.overrides=".
- Remove the "#" and replace the characters after the "=" with the override file's pathname.
- Save the file.
- Run "build cd-x86-lite" (or whatever you normally use to build a CDROM image).
This should create the "jnode-x86-lite.iso.vmx" file with the VMX settings from your file as overrides to the default settings.
Unfortunately, VMWare have not released any documentation for the myriad VMX settings. The best 3rd-party documentation that I can find is the sanbarrow.com website. There are also various "builder" applications around, but they don't look all that good.
VMWare disks and Boot device order
If you add a VMWare virtual (or real) disk drive, the VMWare virtual machine's BIOS will try to boot from that drive. Unless you have set up the drive to be bootable, this won't work. The easy way to fix this is to change VMWare's BIOS settings to alter the boot device order.
- Run vmplayer as above.
- Quickly click the VMWare window to give it keyboard focus and hit [F2]. (You have small window to do this ... just a second or two!).
- In the BIOS settings screen, select the "Booting" panel and move the "cdrom" to the top; i.e. the first device to be tried.
- Save the BIOS settings to the virtual NVRAM and exit the BIOS settings editor to continue the boot.
By default the NVRAM settings are stored in the "JNode.nvram" file in "all/build/cdroms" directory, and will be clobbered when you run "build clean". If this is a problem, create a VMX override (see above) with a "nvram" entry that uses a different location for the file.
Running on a PC
To run JNode on a PC using the bootable CDROM, your PC must comply with the following specifications:
- Pentium or above CPU
128Mb RAM or more (i'm not sure what the minimum is) - Bootable CDROM drive that supports El-Torito harddisk emulation
- VGA compatible video card
- Keyboard
The GRUB Boot Menu
The first JNode related information you will see after booting from a JNode CDROM image is the GRUB bootloader page. The GNU GRUB bootloader is responsible for selecting a JNode configuration from a menu, loading the corresponding kernel image and parameters into RAM and causing the JNode kernel to start executing.
When GRUB starts, it displays the bootloader page and pauses for a few seconds. If you do nothing, GRUB will automatically load and start the default configuration. Pressing any key at this point will interrupt the automatic boot sequence and allow you to select a specific configuration. You can use the UP-ARROW and DOWN-ARROW to choose a JNode configuration, then hit ENTER to boot it up.
There are a number of JNode configurations in the menu:
- The configurations that include "MP" in the description enable JNode's multiprocessor support on a capable machine. Since JNode's multiprocessor support is not fully functional, you should probably avoid these configurations for now.
- The configurations the include "GUI" in the description will start up the JNode GUI. Configurations without this tag will start up the JNode command shell on a text console.
- The other difference between the configurations is in the sets of plugins that they load. In general, loading more plugins will cause JNode to use more RAM.
It is currently not a good idea to boot JNode straight to the GUI. If want to run the GUI, it is best to boot the one of the non-GUI configurations; typically "JNode (all plugins)". Then from the text console, run the following commands:
JNode /> gc
JNode /> startawt
Hardware Compatibility List
Use this list to find out if JNode already supports your hardware.
If you find out that your device is not on the list, or the information provided here is incorrect, please submit
your changes.
Hardware requirements
To be able to run JNode, you're hardware should be at least equal to or better then:
- Pentium class CPU with Page Size Extensions (PSE) feature
- 512MB RAM
In order to run JNode the following hardware is recommended:
- Pentium i3 or better
- 1GB RAM
- CDROM drive
- Modern VGA card (see devices)
JNode Commands
This page contains the available documentation for most of the useful JNode commands. For commands not listed below, try running help <alias> at the JNode command prompt to get the command's syntax description and built-in help. Running alias will list all available command aliases.
If you come across a command that is not documented, please raise an issue. (Better still, if you have website content authoring access, please add a page yourself using one of the existing command pages as a template.)
acpi
acpi
| Synopsis | ||
| acpi | displays ACPI details | |
| acpi | --dump | -d | lists all devices that can be discovered and controlled through ACPI |
| acpi | --battery | -b | displays information about installed batteries |
|
Details | ||
|
The acpi command currently just displays some information that can be gleaned from the host's "Advanced Configuration & Power Interface" (ACPI). In the future we would like to interact with ACPI to do useful things. However, this appears to be a complex topic, rife with compatibility issues, so don't expect anything soon.
The ACPI specifications can be found on the net, also have a look at wikipedia. |
||
|
Bugs | ||
| This command does nothing useful at the moment; it is a work in progress. | ||
alias
alias
| Synopsis | ||
| alias | prints all available aliases and corresponding classnames | |
| alias | <alias> <classname> | creates an alias for a given classname |
| alias | -r <alias> | removes an existing alias |
|
Details | ||
|
The alias command creates a binding between a name (the alias) and the fully qualified Java name of the class that implements the command. When an alias is created, no attempt is made to check that the supplied Java class name denotes a suitable Java class. If the alias name is already in use, alias will update the binding.
If the classname argument is actually an existing alias name, the alias command will create a new alias that is bound to the same Java classname as the existing alias. A command class (e.g. one whose name is given by an aliased classname) needs to implement an entry point method with one of the following signatures:
If a command class has both execute and main methods, most invokers will use the former in preference to the latter. Ideally, a command class should extend org.jnode.shell.AbstractCommand. |
||
arp
arp
| Synopsis | ||
| arp | prints the ARP cache | |
| arp | -d | clears the ARP cache |
|
Details | ||
|
ARP (the Address Resolution Protocol) is a low level protocol for discovering the MAC address of a network interface on the local network. MAC address are the low-level network addresses for routing IP (and other) network packets on a physical network.
When a host needs to comminutate with an unknown local IP address, it broadcasts an ARP request on the local network, asking for the MAC address for the IP address. The node with the IP address broadcasts a response giving the MAC address for the network interface corresponding to the IP address. The ARP cache stores IP to MAC address mappings that have previously been discovered. This allows the network stack to send IP packets without repeatedly broadcasting for MAC addresses. The arp command allows you to examine the contents of the ARP cache, and if necessary clear it to get rid of stale entries. |
||
basename
basename
| Synopsis |
| basename String [Suffix] |
| Details |
| Strip directory and suffix from filenames |
| Compatibility |
| JNode basename is posix compatible. |
| Links |
beep
beep
| Synopsis | ||
| beep | makes a beep noise | |
|
Details | ||
| Useful for alerting the user, or annoying other people in the room. | ||
bindkeys
bindkeys
| Synopsis | ||
| bindkeys | print the current key bindings | |
| bindkeys | --reset | reset the key bindings to the JNode defaults |
| bindkeys | --add <action> (<vkSpec> | <character>) | add a key binding |
| bindkeys | --remove <action> [<vkSpec> | <character>] | remove a key binding |
|
Details | ||
|
The bindkeys command prints or changes the JNode console's key bindings; i.e. the mapping from key events to input editing actions. The bindkeys form of the command prints the current bindings to standard output, and the bindkeys --reset form resets the bindings to the hard-wired JNode default settings.
The bindkeys --add ... form of the command adds a new binding. The <action> argument specifies an input editing action; e.g. 'KR_ENTER' causes the input editor to append a newline to the input buffer and 'commit' the input line for reading by the shell or application. The <vkSpec> or <character> argument specifies an input event that is mapped to the <action>. The recognized <action> values are listed in the output the no-argument form of the bindkeys command. The <vkSpec> values are formed from the "VK_xxx" constants defined by the "java.awt.event.KeyEvent" class and "modifier" names; e.g. "Shift+VK_ENTER". The <character> values are either single ASCII printable characters or standard ASCII control character names; e.g. "NUL", "CR" and so on. The bindkeys --add ... form of the command removes a single binding or (if you leave out the optional <vkSpec> or <character> argument) all bindings for the supplied <action>. |
||
|
Bugs | ||
|
Changing the key bindings in one JNode console affects all consoles.
The bindkeys command provides no online documentation for what the action codes mean / do. |
||
bootp
bootp
| Synopsis | ||
| bootp | <device> | configures a network interface using BOOTP |
|
Details | ||
| The bootp command configures the network interface given by <device> using settings obtained using BOOTP. BOOTP is a network protocol that allows a host to obtain its IP address and netmask, and the IP of the local gateway from a service on the local network. | ||
bsh
bsh
| Synopsis | ||
| bsh | [ --interactive | -i ] [ --file | -f <file> ] [ --code | -c <code> ] | Run the BeanShell interpreter |
| Details | ||
The bsh command runs the BeanShell interpreter. The options are as follows:
If no arguments are given, --interactive is assumed. |
||
bzip2
bzip2
| Synopsis |
|
bzip2 [Options] [File ...] bunzip2 [Options] [File ...] bzcat [File ...] |
| Details |
| The bzip2 program handles compression and decompression of files in the bzip2 format. |
| Compatibility |
| JNode bzip2 aims to be fully compatible with BZip2. |
| Links |
cat
cat
| Synopsis | ||
| cat | copies standard input to standard output | |
| cat | <filename> ... | copies files to standard output |
| cat | --urls | -u <url> ... | copies objects identified by URL to standard output |
|
Details | ||
The cat command copies data to standard output, depending on the command line arguments:
The name "cat" is borrowed from UNIX, and is short for "concatenate". |
||
|
Bugs | ||
| There is no dog command. | ||
cd
cd
| Synopsis | ||
| cd | [ <dirName> ] | change the current directory |
|
Details | ||
|
The cd command changes the "current" directory for the current isolate, and everything running within it. If a <dirName> argument is provided, that will be the new "current" directory. Otherwise, the current directory is set to the user's "home" directory as given by the "user.home" property.
JNode currently changes the "current" directory by setting the "user.dir" property in the system properties object. |
||
|
Bugs | ||
| The global (to the isolate) nature of the "current" directory is a problem. For example, if you have two non-isolated consoles, changing the current directory in one will change the current directory for the other, | ||
class
class
| Synopsis | ||
| class | <className> | print details of a class |
|
Details | ||
| The class command allows you to print some details of any class on the shell's current classpath. The <className> argument should be a fully qualified Java class name. Running class will cause the named class to be loaded if this hasn't already happened. | ||
classpath
classpath
| Synopsis | ||
| classpath | prints the current classpath | |
| classpath | <url> | adds the supplied url to the end of the classpath |
| classpath | --clear | clears the classpath |
| classpath | --refresh | cause classes loaded from the classpath to be reloaded on next use |
|
Details | ||
|
The classpath command controls the path that the command shell uses to locate commands to be loaded. By default, the shell loads classes from the currently loaded plug-ins. If the shell's classpath is non-empty, the urls on the path are searched ahead of the plug-ins. Each shell instance has its own classpath.
If the <url> argument ends with a '/', it will be interpreted as a base directory that may contain classes and resources. Otherwise, the argument is interpreted as the path for a JAR file. While "file:" URLs are the norm, protocols like "ftp:" and "http:" should also work. |
||
clear
clear
| Synopsis | ||
| clear | clear the console screen | |
|
Details | ||
| The clear command clears the screen for the current command shell's console. | ||
compile
compile
| Synopsis | ||
| compile | [ --test ] [ --level <level> ] <className> | compile a class to native code |
|
Details | ||
|
The compile command uses the native code compiler to compile or recompile a class on the shell's class path. The <className> argument should be the fully qualified name for the class to be compiled
The --level option allows you to select the optimization level. The --test option allows you to compile with the "test" compilers. This command is primarily used for native code compiler development. JNode will automatically run the native code compiler on any class that is about to be executed for the first time. |
||
console
console
| Synopsis | ||
| console | --list | -l | list all registered consoles |
| console | --new | -n [--isolated | --i] | starts a new console running the CommandShell |
| console | --test | -t | starts a raw text console (no shell) |
|
Details | ||
|
The console command lists the current consoles, or creates a new one.
The first form of the console command list all consoles registered with the console manager. The listing includes the console name and the "F<n>" code for selecting it. (Use ALT F<n> to switch consoles.) The second form of the console command starts and registers a new console running a new instance of CommandShell. If the --isolate option is used with --new, the new console's shell will run in a new Isolate. The last form of the console command starts a raw text console without a shell. This is just for testing purposes. |
||
cpuid
cpuid
| Synopsis | ||
| cpuid | print the computer's CPU id and metrics | |
|
Details | ||
| The cpuid command prints the computer's CPU id and metrics to standard output. | ||
date
date
| Synopsis | ||
| date | print the current date | |
|
Details | ||
| The date command prints the current date and time to standard output. The date / time printed are relative to the machine's local time zone. | ||
|
Bugs | ||
|
A fixed format is used to output date and times.
Printing date / time values as UTC is not supported. This command will not help your love life. |
||
del
del
| Synopsis | ||
| del | [ -r | --recursive ] <path> ... | delete files and directories |
| Details | ||
|
The del command deletes the files and/or directories given by the <path> arguments.
Normally, the del command will only delete a directory if it is empty apart from the '.' and '..' entries. The -r option tells the del command to delete directories and their contents recursively. |
||
device
device
| Synopsis | ||
| device | shows all devices | |
| device | <device> | shows a specific device |
| device | ( start | stop | restart | remove ) <device> | perform an action on a device |
|
Details | ||
|
The device command shows information about JNode devices and performs generic management actions on them.
The first form of the device command list all devices registered with the device manager, showing their device ids, driver class names and statuses. The second form of the device command takes a device id given as the <device> argument. It shows the above information for the corresponding device, and also lists all device APIs implemented by the device. Finally, if the device implements the "DeviceInfo" API, it is used to get further device-specific information. The last form of the device command performs actions on the device denoted by the device id given as the <device> argument. The actions are as follows:
|
||
|
Bugs | ||
| This command does not allow you to perform device-specific actions. | ||
df
df
| Synopsis | ||
| df | [ <device> ] | display disk space usage info |
|
Details | ||
| The df command prints disk space usage information for file systems. If a <device>, usage information is displayed for the file system on the device. Otherwise, information is displayed for all registered file systems. | ||
dhcp
dhcp
| Synopsis | ||
| dhcp | <device> | configures a network interface using DHCP |
|
Details | ||
|
The dhcp command configures the network interface given by <device> using settings obtained using DHCP. DHCP is the most commonly used network configuration protocol. The protocol provides an IP address and netmask for the machine, and the IP addresses of the local gateway and the local DNS service.
DHCP allocates IP address dynamically. A DHCP server will often allocate the same IP address to a given machine, but this is not guaranteed. If you require a fixed IP address for your JNode machine, you should use bootp or ifconfig. (And, if you have a DHCP service on your network, you need to configure it to not reallocate your machine's staticly assigned IP address.) |
||
dir
dir
| Synopsis | ||
| dir | [ <path> ] | list a file or directory |
| Details | ||
| The dir command lists the file or directory given by the <path> argument. If no argument is provided, the current directory is listed. | ||
dirname
dirname
| Synopsis |
| dirname String |
| Details |
| Strip non-directory suffix from file names |
| Compatibility |
| JNode dirname is posix compatible. |
| Links |
disasm
disasm
| Synopsis | ||
| disasm | [ --test ] [ --level <level> ] <className> [ <methodName> ] | disassemble a class or method |
|
Details | ||
|
The disasm command disassembles a class or method for a class on the shell's class path The <className> argument should be the fully qualified name for the class to be compiled. The <methodName> should be a method declared by the class. If the method is overloaded, all of the overloads will be disassembled.
The --level option allows you to select the optimization level. The --test option allows you to compile with the "test" compilers. This command is primarily used for native code compiler development. Note, contrary to its name and description above, the command doesn't actually disassemble the class method(s). Instead it runs the native compiler in a mode that outputs assembly language rather than machine code. |
||
echo
echo
| Synopsis | ||
| echo | [ <text> ... ] | print the argument text |
|
Details | ||
| The echo command prints the text arguments to standard output. A single space is output between the arguments, and text is completed with a newline. | ||
edit
edit
| Synopsis | ||
| edit | <filename> | edit a file |
|
Details | ||
|
The edit command edits a text file given by the <filename> argument. This editor is based on the "charva" text forms system.
The edit command displays a screen with two parts. The top part is the menu section; press ENTER to display the file action menu. The bottom part is the text editing window. The TAB key selects menu entries, and also moves the cursor between the two screen parts. |
||
|
Bugs | ||
| This command needs more comprehensive user documentation. | ||
eject
eject
| Synopsis | ||
| eject | [ <device> ... ] | eject a removable medium |
| Details | ||
| The eject command ejects a removable medium (e.g. CD or floppy disk) from a device. | ||
env
env
| Synopsis | ||
| env | [ -e | --env ] | print the system properties or environment variables |
|
Details | ||
|
By default, the env command prints the system properties to standard output. The properties are printed one per line in ascending order based on the property names. Each line consists of a property name, the '=' character, and the property's value.
If the -e or --env option is given, the env command prints out the current shell environment variables. At the moment, this only works with the bjorne CommandInterpreter and the proclet CommandInvoker. |
||
exit
exit
| Synopsis | ||
| exit | cause the current shell to exit | |
|
Details | ||
| The exit command causes the current shell to exit. If the current shell is the JNode main console shell, JNode will shut down. | ||
|
Bugs | ||
| This should be handled as a shell interpreter built-in, and it should only kill the shell if the user runs it directly from the shell's command prompt. | ||
gc
gc
| Synopsis | ||
| gc | run the garbage collector | |
|
Details | ||
|
The gc command manually runs the garbage collector.
In theory, it should not be necessary to use this command. The garbage collector should run automatically at the most appropriate time. (A modern garbage collector will run most efficiently when it has lots of garbage to collect, and the JVM is in a good position to know when this is likely to be.) In practice, it is necessary to run this command:
|
||
grep
grep
| Synopsis |
| grep [Options] Pattern [File ...] |
| grep [Options] [ -e Pattern | -f File ...] [File ...] |
| Details |
| grep searches the input Files (or standard input if not files are give, or if - is given as a file name) for lines containing a match to the Pattern. By default grep prints the matching lines. |
| Compatibility |
|
JNode grep implements most of the POSIX grep standard JNode grep implements most of the GNU grep extensions |
| Links |
| Bugs |
|
gzip
gzip
| Synopsis |
|
gzip [Options] [-S suffix] [File ...] gunzip [Options] [-S suffix] [File ...] zcat [-f] [File ...] |
| Details |
| The gzip program handles the compress and decompression of files in the gzip format. |
| Compatibility |
| JNode gzip aims to be fully compatible with gnu zip. |
| Links |
halt
reboot
| Synopsis | ||
| halt | shutdown and halt JNode | |
|
Details | ||
| The halt command shuts down JNode services and devices, and puts the machine into a state in which it is safe to turn off the power. | ||
help
help
| Synopsis | ||
| help | [ <name> ] | print command help |
|
Details | ||
|
The help command prints help for the command corresponding to the <name> argument. This should be either an alias known to the current shell, or a fully qualified name of a Java command class. If the <name> argument is omitted, this command prints help information for itself.
Currently, help prints command usage information and descriptions that it derives from a command's old or new-style argument and syntax descriptors. This means that (unlike Unix "man" for example), the usage information will always be up-to-date. No help information is printed for Java applications which have no JNode syntax descriptors. |
||
hexdump
hexdump
| Synopsis | ||
| hexdump | <path> | print a hex dump of a file |
| hexdump | -u | --url <url> | print a hex dump of a URL |
| hexdump | print a hex dump of standard input | |
| Details | ||
| The hexdump command prints a hexadecimal dump of a file, a URL or standard input. | ||
history
history
| Synopsis | ||
| history | print the history list | |
| history | [-t | --test] <index> | <prefix> | find and execute a command from the history list |
|
Details | ||
|
The history command takes two form. The first form (with no arguments) simply prints the current command history list. The list is formatted with one entry per line, with each line starting with the history index.
The second form of the history command finds and executes a command from the history list and executes it. If an <index> "i" is supplied, the "ith" entry is selected, with "0" meaning the oldest entry, "1" the second oldest and so on. If a <prefix> is supplied, the first command found that starts with the prefix is executed. The --test (or -t) flag tells the history command to print the selected command instead of executing it. |
||
| Bugs | ||
|
The history command currently does not execute the selected command. This is maybe a good thing.
When the shell executes a command, the history list gets reordered in a rather non-intuitive way. |
||
ifconfig
ifconfig
| Synopsis | ||
| ifconfig | List IP address assignments for all network devices | |
| ifconfig | <device> | List IP address assignments for one network device |
| ifconfig | <device> <ipAddress> [ <subnetMask> ] | Assign an IP address to a network device |
|
Details | ||
|
The ifconfig command is used for assigning IP addresses to network devices, and printing network address bindings.
The first form prints the MAC address, assigned IP address(es) and MTU for all network devices. You should see the "loopback" device in addition to devices corresponding to each of your machine's ethernet cards. The second form prints the assigned IP address(es) for the given <device>. The final form assigns the supplied IP address and associated subnet mask to the given <device>. |
||
|
Bugs | ||
|
Only IPv4 addresses are currently supported.
When you attempt to bind an address, the output shows the address as "null", irrespective of the actual outcome. Run "ifconfig <device>" to check that it succeeded |
||
java
java
| Synopsis | ||
| java | <className> [ <arg> ... ] | run a Java class via its 'main' method |
|
Details | ||
| The java command runs the supplied class by calling its 'public static void main(String[])' entry point. The <className> should be the fully qualified name of a Java class. The java command will look for the class to be run on the current shell's classpath. If that fails, it will look in the current directory. The <arg> list (if any) is passed to the 'main' method as a String array. | ||
kdb
kdb
| Synopsis | ||
| kdb | show the current kdb state | |
| kdb | --on | turn on kdb |
| kdb | --off | turn off kdb |
|
Details | ||
|
The kdb command allows you to control "kernel debugging" from the command line. At the moment, the kernel debugging functionality is limited to copying the output produced by the light-weight "org.jnode.vm.Unsafe.debug(...)" calls to the serial port. If you are running under VMWare, you can configure it to capture this in a file in the host OS.
The kdb command turns this on and off. Kernel debugging is normally off when JNode boots, but you can alter this with a bootstrap switch. |
||
leed, levi
leed & levi
| Synopsis | ||
| leed | <filename> | edit a file |
| levi | <filename> | view a file |
|
Details | ||
|
The leed and levi command respectively edit and view the text file given by the <filename> argument. These commands open the editor in a new text console, and provide simple intuitive screen-based editing and viewing.
The leed command understands the following control functions:
The levi command understands the following control function:
|
||
|
Bugs | ||
| These commands need more comprehensive user documentation. | ||
loadkeys
loadkeys
| Synopsis | ||
| loadkeys | print the current keyboard interpreter | |
| loadkeys | <country> [ <language> [<variant> ] ] | change the keyboard interpreter |
| Details | ||
|
The loadkeys command allows you to change the current keyboard interpreter. A JNode keyboard interpreter maps device specific codes coming from the physical keyboard into device independent keycodes. This mapping serves to insulate the JNode operating system and applications from the fact that keyboards designed for different countries have different keyboard layouts and produce different codes.
A JNode keyboard interpreter is identified by a triple consisting of a 2 character ISO country code, together with an optional 2 character ISO language code and an optional variant identifier. Examples of valid country codes include "US", "FR", "DE", and so on. Examples of language code include "en", "fr", "de" and so on. (You can use JNode completion to get complete lists of the codes. Unfortunately, you cannot get the set of supported triples.) When you run "loadkeys <country> ..., the command will attempt to find a keyboard interpreter class that matches the supplied triple. These classes are in the "org.jnode.driver.input.i10n" package, and should be part of the plugin with the same identifier. If loadkeys cannot find an interpreter that matches your triple, try making it less specific; i.e. leave out the <language> and <variant> parts of the triple. Note: JNode's default keyboard layout is given by the "org/jnode/shell/driver/input/KeyboardLayout.properties" file. (The directory location in the JNode source code tree is "core/src/driver/org/jnode/driver/input/".) |
||
| Bugs | ||
|
Loadkeys should allow you to find out what keyboard interpreter are available without looking at the JNode source tree or plugin JAR files.
Loadkeys should allow you to set the keyboard interpreter independently for each connected keyboard. Loadkeys should allow you to change key bindings at the finest granularity. For example, the user should be able to (say) remap the "Windows" key to "Z" to deal with a broken "Z" key. This would allow you to configure JNode to use a currently unsupported keyboard type. (It would also help those game freaks out there who have been pounding on the "fire" key too much.) |
||
locale
locale
| Synopsis | ||
| locale | print the current default Locale | |
| locale | --list | -l | list all available Locales |
| locale | <language> [ <country> [<variant> ] ] | change the default Locale |
| Details | ||
| The locale command allows you to print, or change JNode's default Locale, or list all available Locales. | ||
log4j
console
| Synopsis | ||
| log4j | --list | -l | list the current log4j Loggers |
| log4j | <configFile> | reloads log4j configs from a file |
| log4j | --url | -u <configURL> | reloads log4j configs from a URL |
| log4j | --setLevel | -s <level> [ <logger> ] | changes logging levels |
|
Details | ||
|
The log4j command manages JNode's log4j logging system. It can list loggers and logging levels, reload the logging configuration and adjust logging levels.
The first form of the log4j command list the currently defined Loggers and there explicit or effective logging levels. An effective level is typically inherited from the "root" logger, and is shown in parentheses. The second and third forms of the log4j command reload the log4j configurations from a file or URL. The final form of the log4j command allows you to manually change logging levels. You can use completion to see what the legal logging levels and the current logger names are. If no <logger> argument is given, the command will change the level for the root logger. |
||
ls
ls
| Synopsis | ||
| ls | [ <path> ... ] | list files and directories |
| Details | ||
| The ls command lists the files and/or directories given by the <path> arguments. If no arguments are provided, the current directory is listed. | ||
| Bugs | ||
| The current output format for 'ls' does not clearly distinguish between an argument that is a file and one that is a directory. A format that looks more like the output for UNIX 'ls' would be better. | ||
lsirq
lsirq
| Synopsis | ||
| lsirq | print IRQ handler information | |
|
Details | ||
| The lsirq command prints interrupt counts and device names for each IRQ. | ||
memory
locale
| Synopsis | ||
| memory | show JNode memory usage | |
| Details | ||
| The memory command shows how much JNode memory is in use and how much is free. | ||
mkdir
mkdir
| Synopsis | ||
| mkdir | <path> | create a new directory |
| Details | ||
| The mkdir command creates a new directory. All directories in the supplied path must already exist. | ||
mount
mount
| Synopsis | ||
| mount | show all mounted file systems | |
| mount | <device> <directory> <fsPath> | mount a file system |
|
Details | ||
|
The mount command manages mounted file systems. The first form of the command shows all mounted file systems showing the mount points and the device identifiers.
The second form of the command mounts a file system. The file system on <device> is mounted as <directory>, with <fsPath> specifying the directory in the file system being mounted that will be used as the root of the file system. Note that the mount point given by <directory> must not exist before mount is run. (JNode mounts the file system as the mount point, not on top of it as UNIX and Linux do.) |
||
namespace
locale
| Synopsis | ||
| namespace | Print the contents of the system namespace | |
| Details | ||
| The namespace command shows the contents of the system namespace. The output gives the class names of the various managers and services in the namespace. | ||
netstat
netstat
| Synopsis | ||
| netstat | Print network statistics | |
|
Details | ||
| The netstat command prints address family and protocol statistics gathered by JNode's network protocol stacks. | ||
onheap
onheap
| Synopsis | ||
| onheap | [--minCount <count>] [--minTotalSize <size>] [--className <size>]* | Print per-class heap usage statistics |
| Details | ||
|
The onheap command scans the heap to gather statistics on heap usage. Then it outputs a per-class breakdown, showing the number of instances of each class and the total space used by those instances.
When you run the command with no options, the output report shows the heap usage for all classes. This is typically too large to be directly useful. If you are looking for statistics for specific classes, you can pipe the output to the grep command and select the classes of interest with a regex. If you are trying to find out what classes are using a lot of space, you can use the onheap command's options to limit the output as follows:
|
||
page
page
| Synopsis | ||
| page | [ <file> ] | page a file |
| page | page standard input | |
| Details | ||
|
The page command displays the supplied file a screen page at a time on a new virtual console. If no arguments are provided, standard input is paged.
The command uses keyboard input to control paging. For example, a space character advances one screen page and ENTER advances one line. Enter 'h' for a listing of the available pager commands and actions. |
||
| Bugs | ||
|
While the current implementation does not pre-read an input stream, nothing will be displayed until the next screen full is available. Also, the entire contents of the file or input stream will be buffered in memory.
A number useful features supported by typical 'more' and 'less' commands have not been implemented yet. |
||
ping
ping
| Synopsis | ||
| ping | <host> | Ping a remote host |
|
Details | ||
| The ping command sends ICMP PING messages to the remote host given by <host> and prints statistics on the replies received. Pinging is a commonly used technique for testing that a remote host is contactable. However, ping "failure" does not necessarily mean that the machine is uncontactable. Gateways and even hosts are often configured to silently block or ignore PING messages. | ||
|
Bugs | ||
| The ping command uses hard-wired parameters for the PING packet's TTL, size, count, interval and timeout. These should be command line options. | ||
plugin
plugin
| Synopsis | ||
| plugin | List all plugins and their status | |
| plugin | <plugin> | List a given plugin |
| plugin | --load | -l <plugin> [ <version> ] | Load a plugin |
| plugin | --unload | -u <plugin> | Unload a plugin |
| plugin | --reload | -r <plugin> [ <version> ] | Reload a plugin |
| plugin | --addLoader | -a <url> | Add a new plugin loader |
|
Details | ||
|
The plugin command lists and manages plugins and plugin loaders.
The no argument form of the command lists all plugins known to the system, showing each one's status. The one argument form lists a single plugin. The --load, --unload and --reload options tell the plugin command to load, unload or reload a specified plugin. The --load and --reload forms can also specify a version of the plugin to load or reload. The --addLoader option configures a new plugin loader that will load plugin from the location given by the <url>. |
||
propset
propset
| Synopsis | ||
| propset | [ -s | --shell ] <name> [ <value> ] | Set or remove a property |
|
Details | ||
|
The propset command sets and removes properties in either the System property space or (if -s or --shell is used) Shell property space. If both <name> and <value> are supplied, the property <name> is set to the supplied <value>. If just <name> is given, the named property is removed.
The System property space consists of the properties returned by "System.getProperty()". This space are currently isolate-wide, but there are moves afoot to make it proclet specific. The Shell property space consists of properties stored by each Shell instance. This space is is separate from an shell interpreter's variable space, and persists over changes in a Shell's interpreter. The 'set' command is an alias for 'propset', but if you are using the 'bjorne' interpreter the 'set' alias is obscured by the POSIX 'set' builtin command which has incompatible semantics. Hence 'propset' is the recommended alias. |
||
pwd
pwd
| Synopsis | ||
| pwd | print the pathname for current directory | |
|
Details | ||
| The pwd command prints the pathname for the current directory; i.e. the value of the System "user.dir" property mapped to an absolute pathname. Note that the current directory is not guaranteed to exist, or to ever have existed. | ||
ramdisk
ramdisk
| Synopsis | ||
| ramdisk | -c | --create [ -s | --size <size> ] | |
| Details | ||
|
The ramdisk command manages RAM disk devices. A RAM disk is a simulated disk device that uses RAM to store its state.
The --create form of the command creates a new RAM disk with a size in bytes given by the --size option The default size is 16K bytes. Note that the RAM disk has a notional block size of 512 bytes, so the size should be a multiple of that. |
||
reboot
reboot
| Synopsis | ||
| reboot | shutdown and reboot JNode | |
|
Details | ||
| The reboot command shuts down JNode services and devices, and then reboots the machine. | ||
remoteout
remoteout
| Synopsis | ||
| remoteout | [--udp | -u] --host | -h <host> [--port | -p <port>] | Copy console output and logging to a remote receiver |
| Details | ||
Running the remoteout command tells the shell to copy console output (both 'out' and 'err') and logger output to a remote TCP or UDP receiver. The options are as follows:
Before you run remoteout on JNode, you need to start a TCP or UDP receiver on the relevant remote host and port. The JNode codebase includes a simple receiver application implemented in Java. You can run as follows: java -cp $JNODE/core/build/classes org.jnode.debug.RemoteReceiver & Running the RemoteReceiver application with the --help option will print out a "usage" message. Notes:
|
||
| Bugs | ||
|
In addition to the inherent lossiness of UDP, the UDPOutputStream implementation can discard output arriving simultaneously from multiple threads.
Logger output redirection is disabled in TCP mode due to a bug that triggers kernel panics. There is currently no way to turn off console/logger copying once it has been started. Running remoteout and a receiver on the same JNode instance, may cause JNode to lock up in a storm of console output. |
||
resolver
resolver
| Synopsis | ||
| resolver | List the DNS servers the resolver uses | |
| resolver | --add | -a <ipAddr> | Add a DNS server to the resolver list |
| resolver | --del | -d <ipAddr> | Remove a DNS server from the resolver list |
| Details | ||
|
The resolver manages the list of DNS servers that the Resolver uses to resolve names of remote computers and services.
The zero argument form of resolver list the IP addresses of the DNS servers in the order that they are used. The --add form adds a DNS aerver (identified by a numeric IP address) to the front of the resolver list. The --del form removes a DNS server from the resolver list. |
||
route
route
| Synopsis | ||
| route | List the network routing tables | |
| route | --add | -a <target> <device> [ <gateway> ] | Add a new route to the routing tables |
| route | --del | -d <target> <device> [ <gateway> ] | Remove a route from the routing tables |
| Details | ||
|
The routing table tells the JNode network stacks which network devices to use to send packets to remote machines. A routing table entry consists of the "target" address for a host or network, the device to use when sending to that address, and optionally the address of the local gateway to use.
The route command manages the routing table. The no-argument form of the command lists the current routing table. The --add and --del add and delete routes respectively. For more information on how to use route to configure JNode networking, refer to the FAQ. |
||
rpcinfo
rpcinfo
| Synopsis | ||
| rpcinfo | <host> | Probe a remote host's ONC portmapper service |
|
Details | ||
| The rpcinfo command sends a query to the OMC portmapper service running on the remote <host> and lists the results. | ||
run
run
| Synopsis | ||
| run | <file> | Run a command script |
|
Details | ||
The run command runs a command script. If the script starts with a line of the form
#!<interpreter> where <interpreter> is the name of a registered CommandInterpreter, the script will be run using the nominated interpreter. Otherwise, the script will be run using the shell's current interpreter. |
||
startawt
startawt
| Synopsis | ||
| startawt | start the JNode Graphical User Interface | |
|
Details | ||
|
The startawt command starts the JNode GUI and launches the desktop class specified by the system property jnode.desktop. The default value is "org.jnode.desktop.classic.Desktop"
There is more information on the JNode GUI page, including information on how to exit the GUI. |
||
syntax
syntax
| Synopsis | ||
| syntax | lists all aliases that have a defined syntax | |
| syntax | --load | -l | loads the syntax for an alias from a file |
| syntax | --dump | -d | dumps the syntax for an alias to standard output | syntax | --dump-all | dumps all syntaxes to standard output |
| syntax | --remove | -r alias | remove the syntax for the alias |
|
Details | ||
|
The syntax command allows you to override the built-in syntaxes for commands that use the new command syntax mechanism. The command can "dump" a command's current syntax specification as XML, and "load" a new one from an XML file. It can also "remove" a syntax, provided that the syntax was defined or overridden in the command shell's syntax manager.
The built-in syntax for a command is typically specified in the plugin descriptor for a parent plugin of the command class. If there is no explicit syntax specification, a default one will be created on-the-fly from the command's registered arguments. Note: not all classes use the new syntax mechanism. Some JNode command classes use an older mechanism that is being phased out. Other command classes use the classic Java approach of decoding arguments passed via a "public static void main(String[])" entry point. |
||
|
Bugs | ||
| The XML produced by "--dump" or "--dump-all" should be pretty-printed to make it more readable / editable. | ||
tar
tar
| Synopsis |
| tar -Acdtrux [Options] [File ...] |
| Details |
| The tar program provides the ability to create tar archives, as well as various other kinds of manipulation. For example, you can use tar on previously created archives to extract files, to store additional files, or to update or list files which were already stored. |
| Compatibility |
| JNode tar aims to be fully compliant with gnu tar. |
| Links |
tcpinout
tcpinout
| Synopsis | ||
| tcpinout | <host> <port> | Run tcpinout in client mode |
| tcpinout | <local port> | Run tcpinout in server mode |
|
Details | ||
|
The tcpinout command is a test utility that sets up a TCP connection to a remote host and then connects the command's input and output streams to the socket. The command's standard input is read and sent to the remote machine, and simultaneously output from the remote machine is written to the command's standard output. This continues until the remote host closes the socket or a network error occurs.
In "client mode", the tcpinout command opens a connection to the supplied <host> and <port>. This assumes that there is a service on the remote host that is "listening" for connections on the port. In "server mode", the tcpinout command listens for an incoming TCP connection on the supplied <local port>. |
||
thread
thread
| Synopsis | ||
| thread | [--groupDump | -g] | Display info for all extand Threads |
| thread | <threadName> | Display info for the named Thread |
| Details | ||
|
The thread command can display information for a single Thread or all Threads that are still extant.
The first form of the command traverses the ThreadGroup hierarchy, displaying information for each Thread that it finds. The information displayed consists of the Thread's 'id', its 'name', its 'priority' and its 'state'. The latter tells you (for example) if the thread is running, waiting on a lock or exited. If the Thread has died with an uncaught exception, you will also see a stacktrace. If you set the --groupDump flag, the information is produced by calling the "GroupInfo.list()" debug method. The output contains more information but the format is ugly. The second form of the thread command outputs information for the thread given by the <threadName> argument. No ThreadGroup information is shown. |
||
| Bugs | ||
|
The output does not show the relationship between ThreadGroups unless you use --groupDump.
The second form of the command should set a non-zero return code if it cannot find the requested thread. There should be a variant for selecting Threads by 'id'. |
||
time
time
| Synopsis |
| time Alias [Args] |
| Details |
| Executes the command given by Alias and outputs the total execution time of that command. |
touch
cd
| Synopsis | ||
| touch | <filename> | create a file if it does not exist |
|
Details | ||
| The touch command creates the named file if it does not already exist. If the <filename> is a pathname rather than a simple filename, the command will also create parent directories as required. | ||
unzip
unzip
| Synopsis |
| unzip [Options] Archive [File ...] [-x Pattern] [-d Directory] |
| Details |
| The unzip program handles the extraction and listing of archives based on the PKZIP format. |
| Compatibility |
| JNode unzip aims to be compatible with INFO-Zip. |
| Links |
utest
utest
| Synopsis | ||
| utest | <classname> | runs the JUnit tests in a class. |
|
Details | ||
| The utest command loads the class given by <className> creates a JUnit TestSuite from it, and then runs the TestSuite using a text-mode TestRunner. The results are written to standard output. | ||
vminfo
vminfo
| Synopsis | ||
| vminfo | [ --reset ] | show JNode VM information |
|
Details | ||
| The vminfo command prints out some statistics and other information about the JNode VM. The --reset flag causes some VM counters to be zeroed after their values have been printed. | ||
wc
wc
| Synopsis |
| wc [-cmlLw] [File ...] |
| Details |
| print newline, word and byte counts for each file. |
| Compatibility |
| JNode wc is posix compatible. |
| Links |
zip
zip
| Synopsis |
| zip [Options] [Archive] [File ...] [-xi Pattern] |
| Details |
| The zip program handles the creation and modification of zip archives based on the PKZIP format. |
| Compatibility |
| JNode zip aims to be compatible with INFO-Zip. |
| Links |
JNode GUI
Starting the JNode GUI
JNode supports a GUI which runs a graphical desktop and a limited number of applications. The normal way to launch the JNode GUI is to boot JNode normally, and then at the console command prompt run the following:
JNode> gc
JNode> startawt
The screen will go blank for some time (30 to 60 seconds is common), and then the JNode desktop will be displayed.
Using the JNode GUI
The JNode GUI enables the following special key bindings:
| <ALT> + <CTRL> + <F5> | Refresh the GUI | |
| <ALT> + <F11> | Leaves the GUI | |
| <ALT> + <F12> | Quits the GUI | |
| <ALT> + <CTRL> + <BackSpace> | Quits the GUI | (Don't use this if you are under Linux/Unix : it will quits Linux GUI) |
Trouble-shooting
If the GUI fails to come up after a reasonable length of time, try using <ALT> + <F12> or <ALT> + <CTRL> + <BackSpace> to return to the text console. When you get back to the console, look for any relevant messages on the current console and on the logger console (<ALT> + <F7>).
One possible cause of GUI not launching is that JNode may run out of memory while compiling the GUI plugins to native code. If this appears to be the case and you are running a virtual PC (e.g. using VMware, etc), try changing the memory size of the virtual PC.
Another possible cause of problems may be that JNode doesn't have a working device driver for your PC's graphics card. If this is the case, you could try booting JNode in VESA mode. To do this, simply boot JNode selecting a "(VESA mode)" entry from the GRUB boot menu.
JNode Shell
Introduction
The JNode command shell allows commands to be entered and run interactively from the JNode command prompt or run from command script files. Input to entered at the command prompt (or read from a script file) is first split into command lines by a command interpreter; see below. Each command line is split into command name (an alias in JNode parlance) and a sequence of arguments. Finally, each command alias is mapped to a class name, and run by a command invoker.
The available aliases can be listed by typing
JNode /> alias<ENTER>
and an aliases syntax and built-in help can be displayed by typing
JNode /> help alias<ENTER>
More extensive documentation for most commands can be found in the JNode Commands index.
Keyboard Bindings
The command shell (or more accurately, the keyboard interpreter) implements the following keyboard events:
| <SHIFT>+<UP ARROW> | Scroll the console up a line |
| <SHIFT>+<DOWN-ARROW> | Scroll the console down a line |
| <SHIFT>+<PAGE-UP> | Scroll the console up a page |
| <SHIFT>+<PAGE-DOWN> | Scroll the console down a page |
| <ALT>+<F1> | Switch to the main command console |
| <ALT>+<F2> | Switch to the second command console |
| <ALT>+<F7> | Switch to the Log console (read only) |
| <ESC> | Show command usage message(s) |
| <TAB> | Command / input completion |
| <UP-ARROW> | Go to previous history entry |
| <DOWN-ARROW> | Go to next history entry |
| <LEFT-ARROW> | Move cursor left |
| <RIGHT-ARROW> | Move cursor right |
| <BACKSPACE> | Delete character to left of cursor |
| <DELETE> | Delete character to right of cursor |
| <CTRL>+<C> | Interrupt command (currently disabled) |
| <CTRL>+<D> | Soft EOF |
| <CTRL>+<Z> | Continue the current command in the background |
| <CTRL>+<L> | Clear the console and the input line buffer |
Note: you can change the key bindings using the bindkeys command.
Command Completion and Incremental Help
The JNode command shell has a sophisticated command completion mechanism that is tied into JNode's native command syntax mechanisms. Completion is performed by typing the <TAB> key.
If you enter a partial command name as follows.
JNode /> if
If you now enter <TAB> the shell will complete the command as follows:
JNode /> ifconfig
with space after the "g" so that you can enter the first argument. If you enter <TAB>
again, JNode will list the possible completions for the first argument as follows:
eth-pci(0,16,0)
loopback
JNode /> ifconfig
This is telling you that the possible values for the first argument are "eth-pci(0,16,0)" and "loopback"; i.e. the names of all network devices that are currently available. If you now enter "l" followed by <TAB>, the shell will complete the first argument as follows:
JNode /> ifconfig loopback
and so on. Completion can be performed on aliases, option names and argument types such as file and directory paths and device and plugin names.
While completion can be used to jolt your memory, it is often useful to be able to see the syntax description for the command you are entering. If you are in the middle of entering a command, entering <CTRL-?> will parse what you have typed in so far against the aliases syntax, and then print the syntax description for the alternative(s) that match what you have entered.
The JNode command shell uses a CommandInterpreter object to translate the characters typed at the command prompt into the names and arguments for commands to be executed. There are currently 3 interpreters available:
- "default" - this bare-bones interpreter splits a line into a simple command name (alias) and arguments. It understands argument quoting, but little else.
- "redirecting" - this interpreter adds the ability to use "<" and ">" for redirecting standard input and standard output, and "|" for simple command pipelines. This is the default interpreter.
- "bjorne" - this interpreter is an implementation of the POSIX shell specification; i.e. it is like UNIX / GNU Linux shells such as "sh", "bash" and "ksh". The bjorne interpreter is still under development. Refer to the bjorne tracking issue for a summary of implemented features and current limitations.
The JNode command shell currently consults the "jnode.interpreter" property to determine what interpreter to use. You can change the current interpreter using the "propset -s" command; e.g.
JNode /> propset -s jnode.interpreter bjorne
Note that this only affects the current console, and that the setting does not persist beyond the next JNode reboot.
Command Invokers
The JNode command shell uses a CommandInvoker object to execute commands extracted from the command line by the interpreter. This allows us to run commands in different ways. There are currently 4 command invokers available:
- "default" - this invoker runs the command in the current Java Thread.
- "thread" - this invoker runs the command in a new Java Thread.
- "proclet" - this invoker runs the command in a new Proclet. The proclet mechanism is a light-weight process mechanism that gives a degree of isolation, so that the command can have its own standard input, output and error streams. The command can also see the "environment" variables of the parent interpreter. This is the default invoker.
- "isolate" - this invoker runs the command in a new Isolate. The isolate mechanism gives the command its own statics, as if the command is executing in a new JVM. Isolates and the IsolateInvoker are not fully implemented.
The JNode command shell currently consults the "jnode.invoker" property to determine what invoker to use. You can change the current invoker using the "propset -s" command; e.g.
JNode /> propset -s jnode.invoker isolate
Note that this only affects the current console, and that the setting does not persist beyond the next JNode reboot.
Testing remote programs in shell
If you want to test some java application, but don't want to recompile JNode completly every time you change your application, you can use the classpath command.
Set up your network, if you don't know how, read the FAQ.
Now you have to setup a webserver or tftp server on your remote mashine, where you place your .class or .jar files.
With the classpath command you can now add a remote path. E.g. "classpath add http://192.168.0.1/path/to/classes/". Using "classpath" without arguments shows you the list of added paths. To start your application simply type the class file's name.
For more info read the original forum topic from Ewout, read more about shell commands or have a look at the following example:
On your PC:
Install a Webserver (e.g. Apache) and start it up. Let's say it has 192.168.0.1 as its IP. Now create a HelloWorld.java, compile it and place the HelloWorld.class in a directory of your Webserver, for me that is "/var/www/localhost/htdocs/jnode/".
Inside JNode:
Type the following lines inside JNode. You just have to replace IP addesses and network device by values matching your configuration.
ifconfig eth-pci(0,17,0) 192.168.0.6
route add 192.168.0.1 eth-pci(0,17,0)
classpath add http://192.168.0.1/jnode/
now that a new classpath is added you can run your HelloWorld App by simply typing
HelloWorld
Performance
Performance of an OS is critical. That's why many have suggested that an OS cannot be written in Java. JNode will not be the fastest OS around for quite some time, but it is and will be a proof that it can be done in Java.
Since release 0.1.6, the interpreter has been removed from JNode, so now all methods are compiled before being executed. Currently two new native code compilers are under development that will add various levels of optimizations to the current compiler. We expect these compilers to bring us much closer to the performance of Sun's J2SDK.
This page will keep track of performance of JNode, measured using various benchmarks, over time.
The performance tests are done on a Pentium4 2Ghz with 1GB of memory.
| ArithOpt, org.jnode.test.ArithOpt | Lower numbers are better. | ||
| Date | JNode Interpreted | JNode Compiled | Sun J2SDK |
| 12-jul-2003 | 1660ms | 108ms | 30ms |
| 19-jul-2003 | 1639ms | 105ms | 30ms |
| 17-dec-2003 | 771ms | 63ms | 30ms |
| 20-feb-2004 | n.a. | 59ms | 30ms |
| 03-sep-2004 | n.a. | 27ms* | 30ms |
| 28-jul-2005 | n.a. | 20ms* | 30ms** |
| Sieve, org.jnode.test.Sieve | Higher numbers are better. | ||
| Date | JNode Interpreted | JNode Compiled | Sun J2SDK |
| 12-jul-2003 | 53 | 455 | 5800 |
| 19-jul-2003 | 55 | 745 | 5800 |
| 17-dec-2003 | 158 | 1993 | 5800 |
| 20-feb-2004 | n.a. | 2002 | 5800 |
| 03-sep-2004 | n.a. | 4320* | 5800 |
| 28-jul-2005 | n.a. | 3660* | 4252** |
*) Using L1A compiler
**) Using J2SDK 1.5.0 (others 1.4.2)
Status
JNode is now working on its second major release (0.3).
This second release will focus on stability, speed and memory usage. Further more it will add a real installer, provide isolates and many more.
In the mean time, we continue to release intermediate releases reflecting the state of development. Feel free to download them and enjoy using them.
Look here for the plans for this upcoming release.
We need your help to make it possible, so join us and help us realize the future of Operating Systems.
Look at the contribute page if you want to help us.
Bellow you will find various reports updated daily about the current state of the project:
Changelog
Changes from JNode 0.2.8 to current SVN trunc version
Changes from JNode 0.2.7 to JNode 0.2.8
Features ======== progress with OpenJDK integration class library updated to OpenJDK6 b13 JNode now builds with both Java 6 SE and OpenJDK6+IcedTea javac source level and target level raised to 1.6 introduced mauve based regression testing improved isolate support added isolate invoker added Russian keyboard support improved NTFS support added HFS+ formatter progress with Bjorne shell improved modal dialogs console & shell improvements a large number of bug fixes and improvements in the overall system aiming better Java compatibility, stability and performance real world applications starting to work: Jetty + recent Servlet/JSP examples, PHP with Jetty + Quercus, JEdit, Groovy Contributors to this release ============================ Levente Sántha Fabien Duminy Peter Barth Martin Husted Hartvig Stephen Crawley Fabien Lesire Daniel Noll Tim Sparg Stephen Meslin-Weber Sergey Mashkov Ben Bucksch
Incoming changes for the next release
Features
============================
- added gzip/gunzip commands
- added find, head and tail commands
- integration of JIIC as a pure java replacement of mkisofs
Contributors to this release
============================
- name of the author of gzip/gunzip command (who is it ?)
- bananenkasper
- Tim Sparg
- cluster
- Wooden
Special thanks to Jens Hatlak for integrating our patch to JIIC (version named "a "JNode release")
Note to committers : This topic will serve to build the changelogs for the next release (and avoid searching at release time).
Feel free to add the new features and their author (the patch submitter or, by default, you)
Changes from JNode 0.2.6 to JNode 0.2.7
Features
========
Integrated the OpenJDK implementations of Swing and AWT
Improved java.awt.Graphics and Graphics2D
Improved BDF font rendering
Added VESA based frame buffer support
Added a frame buffer based console with custom backgrounds
Implemented software cursor support
Added a JPEG decoder
Various ImageIO improvements
Added a Samba file system (rw) and support for smb:// and nfs:// URLs
Replaced argument syntax and completion framework for shell commands
Converted existing commands to the new syntax framework
Added a configure tool for the JNode build environment
Various bugfixes to networking, memory management, math support, FAT support, and the core VM.
Contributors to this release
============================
Levente Santha
Fabien Duminy
Peter Barth
Martin Husted Hartvig
Stephen Crawley
Fabien Lesire
Chris Boertien
Brett Lawrence
Daniel Noll
Jacob Kofod
Ian Darwin
Helmut Dersch
Stephen Meslin-Weber
Changes from JNode 0.2.5 to JNode 0.2.6
Features
========
More progress with OpenJDK integration
Wildcards support in shell
NTFS improvements
NFS2 read write support
Command shell improvements
Improved support for pipes and command completion
Experimental Bjorne shell implementation
Added support for JDBC drivers
Fixed object serialization
Support for prefrences API
Improved support for native methods
Code hotswapping support
Fixed DNS support
Included Jetty6, Servlet and JSP support
Read-only HFS+ file system
File System API refactoring & improvements
Experimental telnet server
Added CharvaCommander
Improved BDF font rendering
Contributors to this release
============================
Levente Santha
Martin Husted Hartvig
Fabien Duminy
Fabien Lesire
Stephen Crawley
Daniel Noll
Andrei Dore
Ian Darwin
Peter Barth
Robert Murphey
Michael Klaus
Tanmoy Deb
GriffenJBS (jstephen)
Changes from JNode 0.2.4 to JNode 0.2.5
Features
========
Openjdk integration, roughly 80% completed
Included standard javac and javap from openjdk
Targetting Java 6 compatibility
Build process migrated to Java 6
netcat command
Improved Image I/O support
Improved build process (parallel build using fork)
Included BeanShell and Rhino (JavaScript) as scripting languages
(encouraging results with Jython, Kawa (Scheme), JRuby 1.0 and Scala)
Improved Eclipse support
Nanosecond accurate timer
Started JNode installer (grub support)
Improvements in text consoles
Experimental via-rhine NIC driver
PXE booting support for via-rhine
ANT is getting usable
Improved support for mauve based tests
A mechanism for supporting the native keyword for arbitrary applications
Experimental support for isolates (static data isolation, access to fs/net/gui from isolates)
Various gc and memory management related improvements
Improvements to jfat and ext2 filesystems
Promising experiments with JPC running under JNode and running FreeDOS on the JPC/JNode stack
Support for transparency in the GUI
Many improvement to command execution and input/output streams of commands
Introduced 'proclets' - small programs running in the same isolate with their own in/out/err streams
Proper command line editing and input line history for third party command line based programs (like bsh, rhino)
Contributors
============
Andrei Dore
Daniel Noll
Fabien Lesire
Fabien Duminy
Giuseppe Vitillaro
Levente Sántha
Michael Klaus
Martin Husted Hartvig
Peter Barth
Stephen Crawley
Tanmoy Deb
Changes from JNode 0.2.3 to JNode 0.2.4
Changes from JNode 0.2.3 to JNode 0.2.4
- JFat - a FAT32 file system implementation
- RamFS - a simple in-memory file system
- FTPFS - a read-only FTP based file system
- javac command, included with the use of Eclipse JDT compiler
- Integrated standard java tools: jar, native2ascii, serialver etc. from GNU Classpath
- Text console improvements
- Swing based console
- New textconsole based editor
- Many classpath patches
- ImageIO support for PNG, GIF and BMP images from GNU Classpath
- BDF font support
- Changable desktop Look & Feel
- Isolate (JSR 121), not fully supported
- Simple webserver under JNode
- Various bugfixes in the resource loading, ISO9660, socket writing
- Basic support for development under JNode
Changes from JNode 0.2.2 to JNode 0.2.3
Changes from JNode 0.2.2 to JNode 0.2.3
- Many classpath patches
- Improvements in AWT, Swing and desktop support
- Various bugfixes in the JIT compiler, ISO9660 support, JIFS
- Better support for testing JNode with Mauve (mauve plugins, invoker commands)
Changes from JNode 0.2.1 to JNode 0.2.2
Changes from JNode 0.2.1 to JNode 0.2.2
- Added annotation support
- Implemented much improved font renderer (can be enabled by setting the jnode.font.renderer property to "new"
- Various performance improvements of native code compiler (invoke of final methods, optimized tableswitch)
- Massive classpath improvements
- Major GUI improvements
Changes from JNode 0.2.0 to JNode 0.2.1
Changes from JNode 0.2.0 to JNode 0.2.1
- Implemented field alignments to minimize object size
- Added fragmented plugin support
- Added include support for plugin-list files
- Many improvements on the gui
- Fixed OpenMP detection bug
- Many Classpath patches
- Many memory usage improvements
- Updated java.io to use NIO classes
Changes from JNode 0.1.10 to JNode 0.2.0
Changes from JNode 0.1.10 to JNode 0.2.0
- Change J2SDK requirement to 5.0
- Added support for most of the 5.0 language features (except annotations)
- Added automatic creation of java.io.tmpdir
- Many classpath patches
- Automatic mounting of the jifs (information) filesystem
- Added kill command
- Sending output from shell commands to file
- Piping between shell commands
- Kill job/command when pressing ctrl+c in the shell
Old changelogs
You'll find the changelogs for old releases below.
Changes from JNode 0.1.9 to JNode 0.1.10
Changes from JNode 0.1.9 to JNode 0.1.10
- Ported to AMD64
- Improved ACPI structure
- Improved BIOS structure
- Renamed jnodesys.gz bootable image to jnode32.gz / jnode64.gz
- Added classpath command
- Added onheap command
- Added JIFS JNode information filesystem
- Lots of GNU Classpath patches
- Addition of kernel debugger
- Change in method calling approach (improves performance)
Changes from JNode 0.1.8 to JNode 0.1.9
Changes from JNode 0.1.8 to JNode 0.1.9
- Major GUI improvements
- AWT & Swing now work for a large part
- Improve ATI radeon driver
- Lots of classpath updates
Changes from JNode 0.1.7 to JNode 0.1.8
Changes from JNode 0.1.7 to JNode 0.1.8
- Added L1A baseline compiler with register allocation
- Fixed build system for build with J2SDK 5.0
- Major performance improvements
- Detection of multi-processor systems
- Lots of updates of Classpath
- Lots of bugs fixes
Changes from JNode 0.1.6 to JNode 0.1.7
Changes from JNode 0.1.6 to JNode 0.1.7
- Added Code security using Java Security architecture implementation.
- Completed Lance network driver for VMWare 4
- Improved IDE support
- Improved PS2Mouse driver
- Added runtime load/unload/reloading of plugins
- Added runtime load/unload/reloading of device
- Added ATI Radeon driver
- Added Ext2 R/W support
- Added Ext2 Format support
- Added NT bootloader support using NT-GRUB
- Many Classpath updates
- Added reboot support
- Added ATAPI driver
- Added ATAPI-SCSI bridge driver
- Added SCSI CDROM driver
- Added ISO9660 filesystem
- Improved KeyboardInterpreter framework
- Added various keyboard interpreters
- Lots of bugfixes
Changes from JNode 0.1.5 to JNode 0.1.6
Changes from JNode 0.1.5 to JNode 0.1.6
- Added CHARVA based application support. Charva is now fully supported. Try charva.awt.Tutorial for an example
- Added workmanager for asynchronous execution of small pieces of work
- Added device startup timeout detection
- Implemented method inlining
- Removed interpreter, all code is now compiled before being executed
- Improved the garbage collection, it is now triggered after 75% of the free memory has been allocated
- finalization now works according to the specification
- Moved build to Ant 1.6.0
- Addition of initial jar support
- Addition of read-only NTFS filesystem driver
- Update the console management to work with named consoles instead of indexed consoles.
- New shell command available to manage consoles.The command has the alias "console"
Changes from JNode 0.1.4 to JNode 0.1.5
- Added DNS client
- Added read-only ext2 filesystem
- Added initial GUI widget toolkit
- Improved VM performance for interpreted & compiled code
- Extended DeviceToDriverMapper interface to support "best match" drivers
- Changed scheduling to yieldpoint scheduling
- Added thread command
- Added memory command
- Added class command
- Addition of Ramdisk
- Addition of RTL8139 network driver
- Addition of USB keyboard driver
- Addition of USB HUB driver
- Addition of USB mouse driver
- Addition of USB framework
- Addition of TCP over IPv4 layer
- Addition of LOG4J support, debug logging into second console
Changes from JNode 0.1.3 to JNode 0.1.4
- Addition hardware mouse support
- Various bug fixes
- Addition of logging via UDP connection
- Addition of FDISK command
- Addition of ACPI driver
- Addition netboot target in Grub menu
- Addition of DDC1 (monitor data) read-out
- Addition of NVidia driver
- Wheelmouse scrolls text-console
- Addition Mouse driver
- Improved build performance
- Various graphics enhancements
- Addition TrueType Font provider
- Addition Font Manager
Changes from JNode 0.1.2 to JNode 0.1.3
- Addition of a common help system for shell commands
- Addition of Command Line Completion
- Addition of Shell history
- Addition of VMWare SVGA driver
- Addition of VGA driver
- Addition of initial FrameBufferAPI
- Replaced synchronization implementation by thin-locks. It is now much faster!
- Replaced RTC.getTime implementation. It now only creates one calendar for each thread instead of each invocation
- Addition of compile command, to force the compilation of a given class
- Addition of plugin command, to list all known plug-ins
- Replaced invokeinterface implementation by IMT based implementation
- Addition of Interface Method Table (IMT), a selector indexed array with support for index collisions
- Replaced instanceof and checkcast implementation. The new implementation used a superclasses array found in the TIB
- Replaced Virtual Method Table (VMT) by Type Information Block (TIB), an extended version of the old VMT
- Replaced NetworkLayerManager.(un)registerLayer functions with extension-point
- Replaced DeviceManager.(un)registerMapper functions with extension-point
- Addition of plug-in architecture
- Replaced Shell Command interface with an alias mechanism and static void main(String[]) methods
- JNode has been verified to build using J2SDK 1.4.2
Changes from JNode 0.1.1 to JNode 0.1.2
- JNode can now be build using J2SDK 1.4.2 (beta)
- Addition of kernel parameters in systemproperty jnode.cmdline
- Addition of line numbers in stacktrace for compiled methods
- Addition of floppy driver
- Addition of device command
- Addition of bootp command
- Addition of help command
- Addition of halt command
- Addition of netstat command
- Addition of route command
- Addition of arp command
- Addition of ifconfig command
- Addition of BOOTP over IPv4 client
- Addition of UDP over IPv4 layer
- Addition of ICMP over IPv4 layer
- Addition of IPv4 layer
- Addition of ARP layer
- Addition of 3c90x driver
- Addition of RealTek 8029 driver
- Addition of network framework
J2SDK 5.0 feature support
This page gives an overview of the support for J2SDK 5.0 features.
It reflects the status of the SVN trunk.
| Feature | Status | Can be used |
|---|---|---|
| Generics | Supported |  |
| Generics in collection framework | Supported | |
| Enhanced for loop | Supported | |
| Autoboxing/unboxing | Supported | |
| Typesafe enums | Supported | |
| Varargs | Supported | |
| Static import | Supported | |
| Metadata (annotations) | Supported | |
| Covariant return types | Supported | |
Classlib developers guide
Look at GitHub wiki
Developer guide
This part contains all technical documentation about JNode. This part is intended for JNode developers.
Introduction
This chapter is a small introduction to the technical documentation of JNode.
It covers the basic parts of JNode and refers to their specific documentation.
JNode is a Virtual Machine and an Operating System in a single package. This implies that the technical documentation covers both the Virtual Machine side and the Operating System side.
Besides these two, there is one aspect to JNode that is shared by the Virtual Machine and the Operating System. This aspect is the PluginManager. Since every module in JNode is a Plugin, the PluginManager is a central component responsible for plugin lifecycle support, plugin permissions and plugin loading, unloading & reloading.
The picture below gives an overview of JNode and its various components.

It also states which parts of JNode are written in Java (green) and which part are written in native assembler (red).
As can be seen in the picture above, many parts of the class library are implemented using services provided by the JNode Operating System. These services include filesystems, networking, gui and many more.
Getting the sources
For developing JNode you first need to get the sources. There are basically 3 possible ways to get them with different advantages and disadvantages. These possibilities contain:
- Getting the sources from our nightly build server. You can find a tar.bzip2 file from here. This is the fastest way to get the sources, but you should not use it for development as it makes it hard to update your local sources once modified.
- The second possibility is to use SVN, which is our main repository. SVN is easy to use but is a bit slow on the one hand and on the other hand you need access permissions to commit. For getting access permission one has to proove he's able to follow the JNode guidelines.
- For new developers the recommended way is to use git. We have a git repository that is kept in sync and makes it easy to create patches against trunk.
Have a look at the subpages for a more detailed description of the commands.
SVN Usage (Deprecated : we have moved to GitHub)
This page is deprecated since we have moved to GitHub
This is a slight overview of SVN and how to use it. First of all there are three ways to access SVN: svn, svn+ssh and via https. Sourceforge uses WebDAV, that means you can also browse the repository online with your favorite browser, just click on this link.
Subversion uses three toplevel directories named trunk, branches and tags. Trunk can be compared to CVS Head, branches and tags are self-explanatory, I think
To checkout the source simply type:
svn co https://jnode.svn.sourceforge.net/svnroot/jnode/trunk/ jnode
which creates a new directory called jnode (Mind the space between "trunk/" and "jnode"!) . In this directory all stuff of the repository in /jnode/trunk will be copied to jnode/ on your local computer.
svn up|add|commit as expected.
New to subversion is copy, move and delete. If you copy or move a file, the history is also copied or moved, if you e.g. delete a directory it will not show up anymore if you do a new checkout.
If you want to make a branch from a version currently in trunk you can simply copy the content from trunk/ to branches/, e.g. by:
svn copy https://jnode.svn.sourceforge.net/svnroot/jnode/trunk/ https://jnode.svn.sourceforge.net/svnroot/jnode/branches/my-big-change-branch/
I think that's the most important for the moment, for more information have a look at the SVN Handbook located here.
Btw, for using SVN within eclipse you have to install subclipse located here.
Using Git (at GitHub)
The URLs for official git repository at GitHub are listed below :
Site: https://github.com/jnode/jnode Https: https://github.com/jnode/jnode.git SSH: git@github.com:jnode/jnode.git
For those who know what they are doing already and simply want push access, refer to the page on setting up push access. For those that are unfamiliar with git, there are a few git pages below that explain some of the common tasks of setting up and using git. This of course is not meant to be a replacement for the git manual.
Git Manual: http://www.kernel.org/pub/software/scm/git/docs/user-manual.html Git Crash Course for SVN users: http://git.or.cz/course/svn.html
Setting up push access
In order to gain push access to the repository you will have to create a username on the hosting site and upload a public ssh key. Have the key ready as it will as for it when you sign up. If you have a key already you can register your username here and give your username, email and public key. There's no password involved with the account, the only password is the one you put on your ssh key when you create it, if you choose to do so. Its not like there is sensitive material involved, so dont feel compelled to use a password.
In order to generate an ssh key will require ssh be installed. Most linux distributions will have this already. Simply type in:
ssh-keygen
and your key will be generated. Your public key will be in ~/.ssh/ in a file with a .pub suffix, likely id_rsa.pub or id_dsa.pub. Open the file in a text editor (turn off line wrapping if its enabled), and copy/paste the key into your browser. Its important that the line not be broken over multiple lines.
Once your account has been created, send an email to the address found by the Owner tag on the jnode repo website, which is here. Once you are added you will need to configure your git configuration to use the new push url with your username.
When you originally cloned the repository the configuration setup a remote named origin that referenced the public repo using the anonymous pull url. We'll now change that using git-config.
git config remote.origin.url git@github.com:[user]/jnode.git
Of course replacing [user] with your username, which is case sensitive.
Now you should be setup. Please see the page on push rules and etiquette before continuing.
Setting up your local git repo
The first thing you want to do, obviously, is install git if its not already. Once git is intalled we need to clone the public repository to your local system. At this time of this writing this requires about a 130MB download.
First, position your current directory in the location where you want your working directory to be created. Don't create the working directory as git will refuse to init inside an existing directory. For this example we will clone to a jnode directory in ~/git/.
cd ~/git git clone git@github.com:jnode/jnode.git jnode
Once this has finished you will have a freshly created working directory in ~/git/jnode and the git repository itself will be located in ~/git/jnode/.git For more info see Git Manual Chapter 1: Repositories and Branches
This process has also setup what git refers to as a remote. The default remote after cloning is labeled as origin and it refers to the public repository. In order to keep your repository up to date with origin, you will have to fetch them. See Updating with git-fetch for more info.
When fetch pulls in new objects, you may want to update any branches you have locally that are tracking branches on origin. This will almost always be true of the master branch, as it is highly recommended that you keep your master branch 'clean' and in sync with origin/master. It's not necessary, but it may make life easier until you understand git more fully. To update your master branch to that of origin/master simply
git rebase origin master
Then if you wish to rebase your local topic branches you can
git rebase master [branch]
The reason we're using git rebase instead of git merge is because we do not generally want merge commits to be created. This is partly to do with the svn repo that commits will eventually be pulled into. svn does not handle git merges properly, as a git merge object has multiple parent commits, and svn has no concept of parents. Where git employs a tree structure for its commits, svn is more like a linked list, and is therefore strictly linear. This is why its also important to fetch and rebase often, as it will make the transition of moving branches over to the svn repo much easier.
To learn more about branches refer to the git manual. It is highly recommended that new users to git read through chapters 1-4, as this explains alot of how git operates, and you will likely want to keep it bookmarked for quick referencing until you get a handle on things.
For those users that find the git command line a bit much, there is also `git gui` that is a very nice tool. It allows you to do alot of the tasks you would do on the command line via gui. There is also an eclipse plugin that is under development called egit, part of the jgit project implementing a pure java git implementation.
Git Etiquette
Once you have push access to the public git repo, there are a few simple rules i'd like everyone to observe.
1) Do not push to origin/master
This branch is to be kept in sync with the svn repo. This branch is updated hourly. When it is updated, any changes made to it will be lost anyway as the udpate script is setup in overwrite mode. Even with this, if someone goes to fetch changes from origin/master before the update script has had a chance to bring it back in sync, then those people will have an out of sync master, which is a pain for them. To be on the safe side, when pulling from origin master, it doesnt hurt to do a quick 'git log origin/master' before fetching to see if the commit messages have a git-svn-id: in the message. This is embedded by git for commits from svn. If the top commits do not have this tag, then someone has pushed into origin/master.
2) Do not push into branches unless you know whats going on with it.
If you have a branch created on your local repo and you would like to have your changes pulled upstream then push your branch to the repo and ask for it to be pulled. You can push your branch to the public repo by
git push origin [branch]
so long as a branch by that name does not already exist. Once the changes have been pulled the branch will be removed from the public repo. That is unless the branch is part of some further development. You will still have your branch on your local repo to keep around or delete at your leisure.
3) Sign-off on your work.
Although git preserves the author on its commits, svn overwrites this information when it is commited. Also it is your waying of saying that this code is yours, or that you have been given permission to submit it to the project under the license of the project. Commits will not be pulled upstream without a sign-off. The easiest way to set this up is to configure git with two variables.
git config user.name [name] git config user.email [email]
Then when you go to make your commit, add an -s flag to git commit and it will automatically append a Signed-off-by: line to the commit message. This is not currently being enforced project wide, although it should be. Also if someone sends you a patch, you can add a Created-by: tag for that person, along with your own sign-off tag.
Configuration process
JNode has a number of configuration options that can be adjusted prior to performing a build. This section describes those options, the process of configuring those options, and the tools that support the process.
JNode is currently configured by copying the "jnode.properties.dist" file to "jnode.properties" and editing this and other configuration files using a text editor.
In the future, we will be moving to a new command-line tool that interactively captures configuration settings, and creates or updates the various configuration files.
The Configure tool
The Configure tool is a Java application that is designed to be run in the build environment to capture and record JNode's build-time configuration settings. The first generation of this tool is a simple command-line application that asks the user questions according to an XML "script" file and captures and checks the responses, and records them in property files and other kinds of file.
The Configuration tool supports the following features:
- Property types are specified in terms of regexes or value enumerations.
- Properties are specified in terms of a property name and type, with an optional default value.
- Property sets are collections of properties associated with files:
- They are typically loaded from the file, updated by the tool and written back to the file.
- Properties can be expanded into templates XML and Java source files as well as classic Java properties files.
- A "FileAdapter" API allows new file formats to be added as plugin classes.
- Property values are captured in "screens" consists of a sequence of "items" which define the questions that are presented to the user.
- Each "item" consists of a property name and a multi-line "text" that explains the property to the user.
- A screen can be made conditional, with a "guard" property that determines whether or not the properties in the screen are captured.
- A configuration script file can "import" other script files, allowing the configuration process to modularised. All relative pathnames in scripts are resolved relative to the script file that specifies them.
The configuration tool is launched using the "configure.sh" script:
$ ./configure.sh
When run with no command arguments as above, the script launches the tool using the configuration script at "all/conf-source/script.xml". The full command-line syntax is as follows:
./configure.sh ./configure.sh --help ./configure.sh [--verbose] [--debug] <script-file>
The command creates and/or updates various configuration files, depending on what the script says. Before a file is updated, a backup copy is created by renaming the existing file with a ".bak" suffix.
Configuration script files
The Configure tool uses a "script" to tell it what configuration options to capture, how to capture them and where to put them. Here is a simple example illustrating the basic structure of a script file:
<configureScript>
<type name="integer.type" pattern="[0-9]+"/>
<type name="yesno.type">
<alt value="yes"/>
<alt value="no"/>
</type>
<propFile name="test.properties">
<property name="prop1" type="integer.type"
description="Enter an integer"
default="0"/>
<property name="prop2" type="yesno.type"
description="Do you want to?"
default="no"/>
</propFile>
<screen title="Testing set 1">
<item property="prop1"/>
<item property="prop2"/>
</screen>
</configureScript>
The main elements of a script are "types", "property sets" and "screens". Lets describe these in that order.
A "type" element introduces a property type which defines a set of allowed values for properties specified later in the script file. A property type's value set can be defined using a regular expression (pattern) or by listing the value set. For more details refer to the "Specifying property types" page.
A "propFile" element introduces a property set consisting of the properties to be written to a given property file. Each property in the property set is specified in terms of a property name and a previously defined type, together with a (one line) description and an optional default value. For more details refer to the "Specifying property files" page.
A "screen" element defines the dialog sequence that is used to request configuration properties from the user. The screen consists of a list of properties, together with (multi-line) explanations to be displayed to the user. For more details refer to the "Specifying property screens" page.
Finally, the "Advanced features" page describes the control properties and the import mechanism.
Specifying property types
Configuration property types define sets of allowable values that can be used in values defined elsewhere in a script file. A property type can be defined either using a regular expression or by listing the set of allowable values. For example:
<type name="integer.type" pattern="[0-9]+"/>
<type name="yesno.type">
<alt value="yes"/>
<alt value="no"/>
</type>
The first "type" element defines a type whose values are unsigned integer literals. The second one defines a type that can take the value "yes" or "no".
In both cases, the value sets are modeled in terms of the "token" character sequences that are entered by the user and the "value" character sequences that are written to the property files. For a property types specified using regular expressions, the "token" and "value" sequences are the same, with one exception. The exception is that a sequence of zero characters is not a valid input token. So if the "pattern" could match an empty token, you must define an "emptyToken" that the user will use to enter this value. For example, the following defines a variant of the previous "integer.type" in which the token "none" is used to specify that the corresponding property should have an empty value:
<type name="optinteger.type"
pattern="[0-9]*" emptyToken="none"/>
For property types specified by listing the values, you can make the tokens and values different for any pair. For example:
<type name="yesno.type">
<alt token="oui" value="yes"/>
<alt token="non" value="no"/>
</type>
Type values and tokens can contain just about any printable character (modulo the issue of zero length tokens). Type names however are restricted to ASCII letters, digits, '.', '-' and '_'.
Specifying property files
A "propFile" element in a script file specifies details about a file to which configuration properties will be written. In the simplest case, a "propFile" element specifies a file name and a set of properties to be written. For example:
<propFile fileName="jnode.properties">
<property name="jnode.vm.size"
type="integer.type"
description="Enter VM size in Mbytes"
default="512"/>
<property name="jnode.vdisk.enabled" type="yesNo.type"
description="Configure a virtual disk"
default="no"/>
</propFile<
This specifies a classic Java properties file called "jnode.properties" which will contain two properties. The "jnode.vm.size" property will have a value that matches the type named "integer.type", with a default value of "512". The "jnode.vdisk.enabled" will have a value that matches the "yesno.type", defaulting to "no".
The Configure tool will act as follows for the example above.
- It will test to see if the "jnode.properties" file exists in the same directory as the script file.
- If the file exists, it will be read using the java.util.Properties.load method, and the in-memory property set will be populated from the corresponding properties.
- If the property file does not exist, the in-memory property set will be populated from the "default" attributes.
- The "screen" elements will be processed as described in the "" page to capture new property values.
- Finally, the "jnode.properties" file will be created or updated using the java.util.Properties.save method.
Attributes of a "property" element
Each "property" element can have the following attributes:
- name
- This attribute gives the name of the property. Property names should be restricted to ASCII letters, digits, '-', '-' and '_'. This attribute is mandatory.
- type
- This attribute gives the name of the property's type. This attribute is mandatory.
- description
- This attribute gives a short (20 chars or so) description of the property that will be included in the prompt for the property's value. This attribute is mandatory.
- default
- This attribute gives a default value for the property if none is supplied by other mechanisms. This attribute is optional, but if present it must contain a valid value for the property's type.
Attributes of a "propFile" element
The Configure tool will read and write properties in different ways depending on the "propFile" element's attributes:
- fileName
- This attribute specifies the name of the file to be written. Depending on the other attributes, it may also be a source of default values. This attribute is mandatory.
- fileFormat
- This attribute specifies various alternative file formats. Possible values are listed below.
- defaultFile
- This attribute specifies that default property values should be loaded from a default property file.
- templateFile
- This attribute specifies that the output file should be written by expanding the supplied template file, as described below.
- marker
- This attribute specifies an alternative marker character for template expansion; the default is '@'.
Alternative file formats
As described above, the Configure tool supports five different file types: more if you use plugin classes. These are as follows:
- "properties"
- This denotes a classic Java properties file, as documented in the Sun javadocs for the java.util.Properties class.
- "xmlProperties"
- This denotes a XML Java properties file, as documented in the Sun javadocs for the java.util.Prfoperties class (Java 1.5 or later).
- "xml"
- This denotes an XML file whose structure is not known.
- "java"
- This denotes a Java source code file.
- "text"
- This denotes an arbitrary text file.
- other
- org.jnode.configure.adapter.FileAdapter class. The behavior is as described below
The file types "xml", "java" and "text" require the use of a template file, and do not permit properties to be loaded.
Template file expansion
If Configure uses a java.util.Properties.saveXXX method to write properties, you do not have a great deal of control over how the file is generated. For example, you cannot include comments for each property, and you cannot control the order of the properties.
The alternative is to create a template of a file that you want the Configure tool to add properties to. Here is a simple example:
# This file contains some interesting properties # The following property is interesting interesting=@interesting@ # The following property is not at all interesting boring=@boring@
If the file above is specified as the "templateFile" for a property set that includes the "interesting" and "boring" properties, the Configure tool will output the property set by expanding the template to replace "@interesting@" and "@boring@" with the corresponding property values.
The general syntax for @...@ sequences is:
at_sequence ::= '@' name [ '/' modifiers ] '@'
name ::= ... # any valid property name
modifiers ::= ... # one or more modifier chars
The template expansion process replaces @...@ sequences as follows:
- If the <name> matches a property name in the property set, the sequence is replaced with the named property's value, rewritten as described below.
- If the @<name>@ does not match a property name in the property set, the sequence is replaced with an empty string. (This is a change from early versions of the tool which left sequence unchanged.)
- The sequence @@ is replaced a single '@' character.
- It is an error for an "opening" @ to not have a "closing" @ on the same line.
The template expansion is aware of the type of the file being expanded, and performs file-type specific escaping of properties before writing them to the output stream:
- The expander for a "properties" file escapes the value according to the Java property file syntax. Three <modifier> values are supported:
- The '=' modifier causes the property name and value to be expanded; i.e. "<name>=<value>" where the name and value parts are suitably escaped.
- The '!' modifier (with '=') causes an empty property value to be suppressed by replacing the @...@ sequence with an empty string.
- The '#' modifier (with '=') causes an empty property value to be commented out; i.e. "# <name>=<value>"
- The expanders for "xmlProperties" and "xml" files escapes the value so that it can be embedded in the text content of an element.
- The expander for "java" files outputs the value with Java string literal escapes.
Specifying property screens
The "dialog" between the Configure tool and the user is organized into sequences of questions called screens. Each screen is a described by a "screen" element in the configuration script. Here is a typical example:
<screen title="Main JNode Build Settings">
<item property="jnode.virt.platform">
The JNode build can generate config files for use with
various virtualization products.
</item>
<item property="expert.mode">
Some JNode build settings should only be used by experts.
</item>
</screen>
When the Configure tool processes a screen, it first outputs the screen's "title" and then iterates over the "item" elements in the screen. For each item, the tool outputs the multi-line content of the item, followed by a prompt formed from the designated property's description, type and default value. The user can enter a value, or just hit ENTER to accept the default. If the value entered by the user is acceptable, the Configure tool moves to the next item in the screen. If not, the prompt is repeated.
Conditional Screens
The screen mechanism allows you to structure the property capture dialog(s) independently of the property files. But the real power of this mechanism is that screens can be made conditional on properties captured by other screens. For example:
<screen title="Virtualization Platform Settings"
guardProp="jnode.virt.platform" valueIsNot="none">
<item property="jnode.vm.size">
You can specify the memory size for the virtual PC.
We recommended a memory size of least 512 Mbytes.
</item>
<item property="jnode.virtual.disk">
Select a disk image to be mounted as a virtual hard drive.
</item>
</screen>
This screen is controlled by the state of a guard property; viz the "guardProp" attribute. In this case, the "valueIsNot" attribute says that property needs to be set to some value other than "none" for the screen to be acted on. (There is also a "valueIs" attribute with an analogous meaning.)
The Configuration tool uses an algorithm equivalent to the following one to decide which screen to process next:
- The tool builds a work-list of the screens in the script. The screens are added to the list in the order that they are encountered by the script file parser.
- To find the next screen, the tool iterates over the work list entries, looking for the screen one that satisfies one of the following criteria:
- a screen with no guard property, or
- a screen with whose guard property has been set, and
- has a "valueIs" attribute whose value equals the guard property's value, or
- has a "valueIsNot" atttibute whose value does not equal the guard property's value.
- The selected screen is then removed from the work-list and processed as described previously.
- To select the next screen, the tool goes back to step 2), repeating until either the work-list is empty, or none of the remaining screens satisfy the criteria.
Advanced features
The "changed" attribute
The "item" element of a screen can take an attribute called "changed". If present, this contains a message that will be displayed after a property is captured if the new value is different from the previous (or default) value. For example, it can be used to remind the user to do a full rebuild when critical parameters are changed.
Configuration files
The primary JNode build configuration file is the "jnode.properties" file in the project root directory.
Other important configuration files are the plugin lists. These specify the list plugins that make up the JNode boot image and the lists that are available for demand loading in various the Grub boot configurations.
Build process
The build process of JNode consists of the following steps.
- Compilation - Compiles all java source to class files.
- Assembling - Combines all class files into a jar file.
- Boot image building - Preloads the core object into a bootable image.
- Boot disk building - Creates a bootable disk image.
- CD-ROM creation (optional) - Creates a bootable CD-ROM (iso) image
Boot image building
When JNode boots, the Grub bootload is used to load a Multiboot compliant kernel image and boot that image. It is the task of the BootImageBuilder to generate that kernel image.
The BootImageBuilder first loads java classes that are required to start JNode into there internal Class structures. These classes are resolved and the most important classes are compiled into native code.
The object-tree that results from this loading & compilation process is then written to an image in exactly the same layout as an object in memory is. This means that the the necessary heap headers, object headers and instance variables are all written in the correct sequence and byte-ordering.
The memory image of all of these objects is linked with the bootstrapper code containing the microkernel. Together they form a kernel image loaded & booted by Grub.
Boot disk building
To run JNode, in a test environment or create a bootable CD-ROM, a bootable disk image is needed. It is the task of the BootDiskBuilder to create such an image.
The bootable disk image is a 16Mb large disk image containing a bootsector, a partition table and a single partion. This single partition contains a FAT16 filesystem with the kernel image and the Grub stage2 and configuration files.
Build & development environment
This chapter details the environment needed to setup a JNode development environment.
Sub-Projects
JNode has been divided into several sub-projects in order to keep it "accessible". These sub-projects are:
| JNode-All | The root project where everything comes together JNode-Core The core java classes, the Virtual Machine, the OS kernel and the Driver framework |
| JNode-FS | The Filesystems and the various block device drivers |
| JNode-GUI | The AWT implementation and the various video & input device drivers |
| JNode-Net | The Network implementation and the various network device drivers |
| JNode-Shell | The Command line shell and several system commands |
Each sub-project has the same directory structure:
| <subprj>/build | All build results |
| <subprj>/descriptors | All plugin descriptors |
| <subprj>/lib | All sub-project specific libraries |
| <subprj>/src | All sources |
| <subprj>/.classpath | The eclipse classpath file |
| <subprj>/.project | The eclipse project file |
| <subprj>/build.xml | The Ant buildfile |
Eclipse
JNode is usually developed in Eclipse. (It can be done without)
The various sub-projects must be imported into eclipse. Since they reference each other, it is advisably to import them in the following order:
- core
- shell
- fs
- gui
- net
- builder
- distr
- all
- sound
- textui
- cli
For a more details please have a look at this Howto.
IntelliJ IDEA
JetBrains Inc has donated a Open Source License for Intellij IDEA to the dedicated developers working on JNode.
Developers can get a license by contacting Martin.
Setup of the sub-projects is done with using the modules feature like with Eclipse.
One should increase the max memory used in the bin/idea.exe.vmoptions or bin/idea.sh.vmoptions file, edit the -Xmx line to about 350mb. IntelliJ can be downloaded at http://www.jetbrains.com/idea/download/ Use at least version 5.1.1. Note that this version can import Eclipse projects.
Requirements for building under Windows
- Make sure that you have a Sun JDK for Java 1.6.0 at or near the most recent patch level. (Some older patch levels are known to cause obscure problems with JNode builds.)
- Make sure that the pathname for the root directory your JNode tree contains no spaces. (Spaces in the pathname are likely to break the build.)
- Create a "bin" directory to holds some utilities; see below.
- Use the "System" control panel to add the "bin" directory to your windows %PATH%.
- Download the "nasm" assembler from http://nasm.sourceforge.net. (Make sure that you get the Win32 version not the DOS32 version!)
- Open the downloaded ZIP file, and copy the "nasm.exe" file to your "bin" directory. Then rename it to "nasmw.exe".
Now, can start a Windows command prompt, change directory to the JNode root, and build JNode as explained the next section.
Requirements for building under Linux
- Make sure that you have a Sun JDK for Java 1.6.0 at or near the most recent patch level. (Some older patch levels are known to cause obscure problems with JNode builds.)
- Make sure that the 'nasm' assembler is installed. If not, use "System>Add/Remove Software" (or your system's equivalent) to install it.
Building
Running "build.sh" or "build.bat" with no arguments to list the available build targets. Then choose the target that best matches your target environment / platform.
Alternatively, from within Eclipse, execute the "all" target of all/build.xml. Building in Eclipse is not advised for Eclipse version 2.x because of the amount of memory the build process takes. From Eclipse 3.x make sure to use Ant in an external process.
A JNode build will typically generate in the following files:
| all/build/jnodedisk.pln | A disk image for use in VMWare 3.0 |
| all/build/x86/netboot/jnodesys.gz | A bootable kernel image for use in Grub. |
| all/build/x86/netboot/full.jgz | A initjar for use in Grub. |
Some builds also generate an ISO image which you can burn to disk, and then use to boot into JNode from a CD / DVD drive.
IntelliJ Howto
This chapter explains how to use IntelliJ IDEA 4.5.4 with JNode. JetBrains Inc has donated a Open Source License to the dedicated developers working on JNode. The license can optained by contacting Martin.
New developers not yet on the JNode project can get a free 30-day trial license from JetBrains Inc.
Starting
JNode contains several modules within a single CVS module. To checkout and import these modules in IntelliJ, execute the following steps:
- Checkout the jnode module from CVS using IntelliJ's "File -> Check Out from CVS".
Dedicated developer should use a Cvs root like ":ssh:developername@cvs.sourceforge.net:/cvsroot/jnode"
Other should use Anonymous CVS Access and use Cvs root ":pserver:anonymous@cvs.sourceforge.net:/cvsroot/jnode"
- Open the project with "File -> Open project" and select the folder that was choosen as destination in the CVS check out. In the "jnode" folder select the "JNode.ipr" file.
The rest has been setup in the project and you should now be able to start.
Building
You can build JNode within IntelliJ by using the build.xml Ant file. In the right side of IntelliJ you find a "Ant Build" tab where the ant file is found. Run the "help" Target to get help on the build system.
Due to the memory requirements of the build process, it could be better to run the build from the commandline using build.bat (on windows) or build.sh (on unix).
Building on the Mac OSX / Intel platform
(These instructions were contributed by "jarrah".)
I've successfully built jnode on MacOS X from the trunk and the 2.6 sources. Here's what I needed to do:
- I'm using 10.5.2. I'm not sure if it works on 10.4.x.
- Download and install Java SE 6 from the ADC site. I used Developer Preview 9. Note that this only works on 64 bit compatible machines (MacBook Pro's with Core 2 Duo processors are OK). The link to the downloads page is: https://connect.apple.com/cgi-bin/WebObjects/MemberSite.woa/105/wo/aC2LI...
- If you don't want to use Java SE 6 as your default Java (I don't), then edit build.sh and add /System/Library/Frameworks/JavaVM.framework/Versions/1.6/Commands/ before the java command.
- Download and build cdrtools (I used version 2.01.01) from http://cdrecord.berlios.de/private/cdrecord.html. I just installed the mkisofs executable in /usr/local/bin (which is in my path).
- Download and install yasm from http://www.tortall.net/projects/yasm/wiki/Download. I used version 0.6.2.
- Edit all/lib/jnode.xml and change the javac "memoryMaximumSize" attribute to "1024m".
- Edit core/src/openjdk/sun/sun/applet/AppletViewerPanel.java and comment out line 34 "import sun.tools.jar.*;"
- Run "sh build.sh cd-x86-lite".
You should end up with an ISO image called jnode-x86.iso in all/build/cdroms.
Cheers,
Greg
Using OSX and PowerPC for JNode development and testing
Using OSX and PPC for JNode development and testing
What we want is:
1. CVS tool
2. IDE for development
3. A way to build JNode
4. A way to boot JNode for testing
First of all we need to install the XCode tools from apple. Usually it is shipped with your OSX, look in /Applications/Installers/. If it is not there you, you can download it from apple’s site.
1. CVS tool
Well cvs is already in the OSX installation. There are some GUI tools to make the use of cvs easier. SmartCVS is a good one, which you can use it in your windows/PC computer, or linux etc.
2. IDE
Eclipse. 
3. How to build JNode with a ppc machine (not FOR, WITH ppc)
Good for us, JNode build process is based on apache ant, which as a java tool runs everywhere. The only problem is the native assembly parts of JNode. For them JNode build process uses nasm and yasm.
So the only thing we need is to build them for ppc and use them. They will still make x86 binaries as they are written to do.
First of all we have to get the nasm and yasm sources. The first one is on
http://nasm.sourceforge.net
and the other is on
http://www.tortall.net/projects/yasm/
After that we unzip them and start the compile.
NASM
Open a terminal window and go inside the directory with the nasm sources
Run ./configure to create the Makefile for nasm
If everything is ok you now are ready to compile nasm. Just run ‘’make nasm‘’. Maybe there will be a problem if you try to compile all the nasm tools by running ‘’make’’ (I had), but you dont need them. Nasm is enought.
Now copy nasm in your path. /usr/bin is a good place.
YASM
The same as for nasm open a terminal window and go to the directory with yasm sources.
Run ‘’./configure’’
Run ‘’make’’
Now you can either copy yasm to /usr/bin or run ‘’make install’’ which will install the yasm tools under /usr/local/bin.
That’s all with nasm and yasm. You are ready to build JNode. You may have problems using the buildl.sh script, but you can always run the build command manually ‘’java -Xmx512M -Xms128M -jar core/lib/ant-launcher.jar -lib core/lib/ -lib /usr/lib/java/lib -f all/build.xml cd-x86’’
4. Booting JNode
Well there is only one way to do that. Emulation.
There is VirtualPC for OSX, which is pretty good and fast. To use it just create a new virtual PC and start it. When the virtual PC is started right click on the CD-Rom icon at the bottom of the window (hmm I know there is no right click on macs  I assume you know to press ctrl+click). Now tell the VirtualPC to use the JNode iso image as cdrom drive and boot from it. There you are!
I assume you know to press ctrl+click). Now tell the VirtualPC to use the JNode iso image as cdrom drive and boot from it. There you are!
I think there is also qemu for ppc. I have not ever used it, so I don’t know how you can configure it.
Source files & packages
This chapter explains the structure of the JNode source tree and the JNode package structure.
Directory structure
The JNode sources are divided into the following groups:
- all
Contains the global libraries, the (Ant) build files and some configuration files. This group does not contain java sources. - builder
Contains the java source code used to build JNode. This includes several Ant tasks, but also code used to link Elf files and to write the JNode bootimage. - core
Contains the JNode virtual machine code (both java and assembler), the classpath java library sources and the core of the JNode operating system, including the plugin manager, the driver framework, the resource manager and the security manager. This is by far the largest and most complex group. - distr
Contains the first parts of the JNode distribution. This includes an installation program and various applications. - fs
Contains the file system framework, the various file system implementation and the block drivers such as the IDE driver, harddisk driver, CD-ROM etc. - gui
Contains the JNode gui implementation. This includes the graphics drivers, the AWT peer implementation, font renderers and the JNode desktop. - net
Contains the JNode network layer. This includes the network drivers, the network framework, the TCP/IP stack and the connection between the network layer and the java.net package. - shell
Contains the JNode command shell and several system shell commands. - textui
Contains a copy of the charva text based AWT implementation. - cli
Contains the bulk of JNode's commands.
Every group is a directory below the root of the JNode CVS archive. Every group contains one or more standard directories.
- build
This directory is created during the build and contains the intermediate build results. - descriptors
This directory contains the plugin descriptors of the plugins defined in this group. - lib
This directory contains libraries (jar files) required only by this group. An exception is the All group, for which the lib directory contains libraries used by all groups. - src
This directory contains the source files. Below this directory there are one or more source directories (source folders in Eclipse) containing the actual source trees.
JNode coding DOs and DONTs
This page lists some tips on how to write good JNode code.
Please add other tips as required.
- Avoid using System.in, System.out, System.err
- Where possible, avoid using these three variables. The problem is that they are global to the current isolate, and are not necessarily connected to the place that you expect them to be.
In a user-level command should use streams provided by the Command API; e.g. by calling the 'getInput()' method from within the command's 'execute' method. Device drivers, services and so on that do not have access to these streams should use log4j logging.
- Avoid cluttering up the console with obscure or unnecessary logging
- If a message is important enough to be written to the console, it should be self explanatory. If it is unimportant, it should be logged using log4j at an appropriate level. We really do not need to see console messages left over from someone's attempts to debug something 12 months ago ...
- Avoid using Unsafe.debug(...) methods
- The org.jnode.vm.Unsafe.debug(...) methods write to the VGA screen and (when kernel debug is enabled) to the serial port. This is ugly, and should be reserved for important early boot sequence logging, VM and GC debugging, and other situations where log4j logging cannot be used.
- Don't call 'Throwable.printStackTrace' and friends
- Commands should allow unexpected exceptions to propagate to the shell level where they are handled according to the user's setting of the 'jnode.debug' property. (The alternative of adding a "--debug" flag to each command, is a bad idea. It is a lot of work and will tend to lead to inconsistencies of implementation; e.g. commands that don't implement "--debug", send "--debug" output to unexpected places, overload other functionality on the flag, etcetera.)
Services, etc should make appropriate log4j calls, passing the offending Throwable as an argument.
- Do use JNode's Command and syntax.* APIs for commands
- Commands that are implemented using the Command and syntax.* APIs support completion and help, and are more likely to behave "normally"; e.g. with respect to stream redirection. There are lots of examples in the codebase.
If the APIs don't do what you want, raise an issue. Bear in mind that some requests may be deemed to be "to hard", or to application specific.
- Do include a 'main' entry point.
- It is a good idea to include a legacy "public static void main(String[])" entry point in each JNode command. This is currently only used by the old "default" command invoker, but in the future it may be used to run the command in a classic JVM.
- Don't use '\n\r' or '\r\n" in output.
- The line separator on JNode is '\n', like on UNIX / Linux. If you expect your command to only run on JNode, it is not unreasonable to hardwire '\n' in output messages, etc. But if you want your command to be portable, it should use 'System.getProperty("line.separator")', or one of the PrintWriter / PrintStream's 'println' methods.
JNode Java style rules
All code that is developed as part of the JNode project must conform to the style set out in Sun's "Java Style Guidelines" (JSG) with variations and exceptions listed below. Javadocs are also important, so please try to make an effort to make them accurate and comprehensive.
Note that we use CheckStyle 4.4 as our arbiter for Java style correctness. Run "./build.sh checkstyle" to check your code style before checking it in or submitting it as a patch. UPDATE: And also, please run "./build.sh javadoc" to make sure that you haven't introduced any new javadoc warnings.
- No TAB characters.
- No TAB characters (HT or VT) are allowed in JNode Java source code.
Whitespace TABs should be replaced with the requisite number of spaces or newlines. Non-whitespace TABs (i.e. in Java strings) should be replaced with "\t" or "\f" escape sequences.
- Use 4 space indentation.
- Two or three characters is too little, eight is too much.
- Maximum line width 120.
- The JSG recommends 80 characters, but most people use tools that can cope with much wider.
- Put following keywords on same line as }
-
For example:
try { if (condition) { something(); } else { somethingElse(); } } catch (Exception ex) { return 42; }Note that the else is on the same line as the preceding }, as is the catch.
- Indent labels by -4.
- For example:
public void loopy() { int i; LOOP: for (i = 100; i < 1000000; i++) { if (isPrime(i) && isPrime(i + 3) && isPrime(i + 5) { break LOOP; } } } - No empty { } blocks
- A { } block with no code should contain a comment to say why the block is empty. For example,
try { myStream.close(); } catch (IOException ex) { // we can safely ignore this } - No marker comments
- It is generally accepted that marker comments (like the following) add little to the readability of a program. In fact, most programmers think they are an eyesore and a waste of space.
//******************************************************* // // Start of private methods // //******************************************************* - Avoid copying javadoc
- Instead of copying the javadoc from the parent class or method, use the {@inheritDoc} tag and if needed add some specific javadoc.
/** * {@inheritDoc} */ public void myMethod(String param1, int param2) { } - Give your references in the javadoc
- When you are implementing a class from a reference document, add a link in the javadoc.
Packages
The java classes of JNode are organized using the following package structure.
Note that not all packages are listed, but only the most important. For a full list, refer to the javadoc documentation.
All packages start with org.jnode.
Common packages
- org.jnode.boot
Contains the first classes that run once JNode is booted. These classes initialize the virtual machine and start the operating system. - org.jnode.plugin
Contains the interfaces of the plugin manager. - org.jnode.util
Contains frequently used utility classes. - org.jnode.protocol
Contains the protocol handlers for the various (URL) protocols implemented by JNode. Every protocol maps onto a package below this package, e.g. the plugin protocol handler is implemented in org.jnode.protocol.plugin.
JNode virtual machine
- org.jnode.vm
Contains the core classes of the JNode virtual machine. - org.jnode.vm.classmgr
Contains the internal classes that represent java classes, methods & field. It also contains the classfile decoder. - org.jnode.vm.compiler
Contains the base classes for the native code compilers that convert java bytecodes into native code for a specific platform. - org.jnode.vm.memmgr
Contains the java heap manager, including the object allocator and the garbage collector. - org.jnode.vm.<arch>
For every architecture that is supported by JNode a seperate package exists, that contains the architecture dependent classes, including classes for threads and processors and classes for the native code compilation.
JNode operating system
- org.jnode.driver
Contains the driver framework.
All drivers and driver API's have a seperate package below this package. Drivers of a similar type are grouped, e.g. all video drivers have a package below org.jnode.driver.video. - org.jnode.system
Contains the interfaces for the various low level resources in the system, such as memory regions, I/O port regions, DMA access. - org.jnode.fs
Contains the filesystem framework.
All file systems have a seperate package below this package, e.g. the EXT2 filesystem implementation is contained in the org.jnode.fs.ext2 package and its sub-packages. - org.jnode.net
Contains the network layer.
All network protocols have a seperate package below this package, e.g. the IPv4 protocol and its sub-protocols is contained in the org.jnode.net.ipv4 package and its sub-packages. - org.jnode.shell
Contains the command shell.
All system commands are grouped in packages below this package.
Special packages
There are some packages that do not comply to the rule that all packages start with org.jnode. These are:
- java.*, javax.*
Contains the classpath implementation of the standard java libraries. - gnu.*
Contains implementation classes of the the classpath library. - org.vmmagic.pragma
Contains exception classes and interfaces that have special meaning to the virtual machine and especially the native code compilers. These classes are mostly shared with the Jikes RVM - org.vmmagic.unboxed
Contains non-normal classes that are used as pointers to raw memory, object references and architecture dependent integers (words). These classes have a special meaning to the virtual machine and especially the native code compilers and should never be instantiated or used without a good knowledge of their meaning. These classes are mostly shared with the Jikes RVM
Source file requirements
Header
All java source files must contain the standard JNode header found in <jnode>/all/template/header.txt.
Do not add extra information to the header, since this header is updated automatically, at which time these extra pieces of information are lots.
Add any extra information about the class to the classes javadoc comment. If you make significant contribution to a class, feel free to add yourself as an @author. However, adding a personal copyright notice is "bad form", and unnecessary from the standpoint of copyright law. (If you are not comfortable with this, please don't contribute code to the project.)
Encoding
All Java source files and other text-based files in the JNode project must be US-ASCII encoded. This means that extended characters in Java code must be encoded in the '\uxxxx' form. Lines should end with an ASCII linefeed (LF) character, not CR LF or LF CR, and hard tab (HT) characters should not be used.
If there is a pressing need to break these rules in some configuration or regression data file, we can make an exception. However, it is advisable to highlight the use of "nasty" characters (e.g. as comments in the file) so that someone doesn't accidentally "fix" them.
Plugin framework
In JNode, all code, services and resources are packaged into plugins.
Each plugin has a descriptor that defines the packages it contains, the plugins it depends on, and any extensions. The plugin-descriptors are held in the descriptors/ directory of each subproject. During the build, once the subprojects have been compiled, the plugins are assembled based on the descriptors that are found.
Plugins are collectively packaged into an initjar. This jar file is passed on the command line to grub when booting JNode and defines what is available to JNode during boot (drivers and such), as well after boot (commands/applications).
-- JNode Plugins --
A JNode plugin is defined by an xml file, its descriptor, contained in the descriptors/ directory of the subproject it belongs too. Filesystem plugins are in fs/descriptors, shell plugins in shell/descriptors and so on.
The root node of a plugin descriptor is >plugin< which takes a few required arguments that give the id, name, version and license.
id : the plugin id. This is the name that other plugins will use for dependencies, and the plugin-list will
use to include the plugin in an initjar.
name : A short descriptive name of what the plugin is.
version : The version of the plugin. For non-jnode plugins, this should be the version of the software being
included. For JNode plugins, use @VERSION@.
license-name : the name of the license the code in the plugin defines. JNode uses lgpl
provider-name : The name of the project that provided the code, JNode.org for jnode plugins.
class(optional) : If the plugin requires special handling when loading/unloading the plugin, it can define a
class here that extends org.jnode.plugin.Plugin, overriding the start() and stop() methods.
Under the <plugin> node are definitions for different parts of the plugin. Here you define what the plugin includes, what it depends on, and any extensions.
The <runtime> node defines what a plugin is to include in its jar-file.
<runtime>
<library> name="foo.jar>
<export name="foo.*">
</library>
</runtime>
This will export the classes that match foo.* in foo.jar to a jar file. This is how you would include classes from a non-jnode library into a plugin for use in jnode. To have a plugin include jnode-specific classes, the library name is of the form "jnode-
To declare dependencies for a plugin, a list of <import> nodes under a <requires> node is required.
<requires> <import plugin="org.jnode.shell"/> </requires>
Will add a dependency to the org.jnode.shell plugin for this plugin. The dependency does two things. When a plugin is included in a plugin-list, its dependencies must also be included, or the initjar builder will fail.
Each plugin has its own classloader. If commands or applications defined in a plugin are run, instead of using a classpath to find classes and jars, the plugin uses the dependencies to search for the proper classes. Every plugin class loader has access to the system plugins, its own plugin, and any plugins listed as dependencies. This means that no plugin needs to require a system plugin.
The last part of a plugin are the extensions. These are not specific to plugins, but rather to different parts of jnode that use the plugin. An extension is defined as :
<extension point="some.extension.point">
The content of an extension is defined by its point. Below is a brief list of extension points and where to find documentation on them.
Shell Extensions
point="org.jnode.shell.aliases"
Used to define aliases for the alias manager in the shell.
point="org.jnode.shell.syntaxes"
Used to define a syntax for command line arguments to an alias.
Core Extensions
point="org.jnode.security.permissions"
Used to define a syntax for command line arguments to an alias.
Core Extensions
point="org.jnode.security.permissions"
Used to define what permissions the plugin is granted.
-- Plugin List --
A plugin list is used to build an initjar and includes all the plugin jars that are defined in its list. The default plugin lists are in all/conf and these lists are read, and their initjars built by default. To change this behavior there are two options in jnode.properties that can be added to tell the build system where to look for custom plugin-lists, and also to turn off building the default plugins.
jnode.properties
custom.plugin-list.dir =Directory can be any directory. ${root.dir} can be used to prefix the path with the directory of your jnode build. no.default.initjars = 1 Set to 1 to disable building the default initjars
A plugin list has a very simple definition. The root node is <plugin-list> that takes a single name attribute that will be the name of the actual initjar. The list of plugins are defined by adding <plugin id="some.plugin"> entries. If a plugin is included that has dependencies, and those plugins are not in the list, the initjar builder will fail.
You can add entries into the initjar manifest file by adding a <manifest> node with a list of <attribute> nodes. Attributes have two arguments, key and value. At a minimum you will want the following manifest entries :
<manifest> <attribute key="Main-Class" value="org.jnode.shell.CommandShell"/> <attribute key="Main-Class-Arg" value="boot"/> </manifest>
This tells jnode, when it finishes initializing, and loads the initjar, that it should run CommandShell.main() with a single argument "boot", so that it knows that this shell is the root shell.
There are many reasons to create your own initjar plugin-list. The most basic reason would be to reduce the overhead of building jnode. By turning off building the default initjars, and defining your own plugin-list for a custom initjar, you can reduce the rebuild time of jnode when making simple changes. It can also allow you to create new plugins and define them in a plugin-list without disturbing the default initjar plugin-lists.
For a basic starting point, the shell-plugin-list.xml creates an initjar that has the minimal plugins for loading jnode and starting a CommandShell. From there you can add plugins that you want, to add various features.
How to add a plugin to JNode
This page will describe how to add a java program to JNode as plugin, so that it can be called via its alias.
First of all you need to set up Eclipse (or your favorit IDE) as described in the readme, so that JNode builds without errors and you can use it (e.g. use JNode in VMWare).
There are different ways of extending JNode with a plugin.
A plugin can contain a class that extends Plugin and (or) normal java programs.
Every plugin is described by a descriptor.
For our example we will develop a plugin that contains a normal java program.
We need a name for our plugin : we will use sample, wich is also the packagename of our plugin.
It belongs to one of the JNodes subprojects in our case we will use the ordername sample in the shell subproject.
Every java-file for our plugin has to be in (or in subfolders):
\shell\src\shell\org\jnode\shell\sample
(for me it is d:\jnode\shell\src\shell\org\jnode\shell\sample)
Now we will write a small HelloWorld.java wich will be one of our plugin programs.
Here is the source of the file HelloWorld.java :
package org.jnode.shell.sample;
public class HelloWorld{
public static void main(String[] args){
System.out.println(“HelloWorld – trickkiste@gmx.de“);
}
}
thats ok, but it will not be build until we create a descriptor and add our plugin to the JNode full-plugin-list.xml.
The plugin descriptor (org.jnode.shell.sample.xml stored in the descriptors folder of the shell subproject) and looks like this :
<?xml version="1.0" encoding="UTF-8"? >
<!DOCTYPE plugin SYSTEM "jnode.dtd">
<plugin id="org.jnode.shell.sample"
name="Sample Plugin"
version="0.2"
license-name="lgpl"
provider-name="Trickkiste">
<requires>
<import plugin="org.jnode.shell"/>
</requires>
<runtime>
<library name="jnode-shell.jar">
<export name="org.jnode.shell.sample.*"/>
</library>
</runtime>
<extension point="org.jnode.shell.aliases">
<alias name="HelloWorld" class="org.jnode.shell.sample.HelloWorld"/>
</extension>
</plugin>
Now we need to add our Plugin to the JNode full-plugin-list.xml, this file is located in jnode\all\conf your entry should look like this :
[...]
<plugin id="org.jnode.util"/>
<plugin id="org.jnode.vm"/>
<plugin id="org.jnode.vm.core"/>
<plugin id="org.jnode.shell.sample"/>
</plugin-list>
thats it, you can now build JNode and test your HelloWorld plugin by typing HelloWorld.
What we can do now is add „normal“ programs to JNode via its provided Pluginstructure.
Command Line Interface
Arguments - The Basics
In JNode's command line interface, the Argument types are the Command programmers main tool for interacting with the user. The Argument provides support to the syntax mechanism to accept parameters, or reject malformed parameters, issuing a useful error message. The argument also supplies completion support, allowing a command to provide specific completions on specific domains.
Organization
At the moment, Arguments are mostly grouped into the shell project under the org.jnode.shell.syntax package. For the time being they will remain here. There is an effort being made to 'untangle' the syntax/argument APIs so this designation is subject to change in the future.
New arguments that are created should be placed into the cli project under the org.jnode.command.argument package if their only use is by the commands under the cli project.
How it works
Every command that accepts an option will require Arguments to capture the options and their associated values. The syntax parser makes use of an argument 'label' to map a syntax node to a specific argument. The parser then asks the Argument to 'accept' the given value. The argument may reject the token if it doesn't not satisfy it's requirements, and provide a suitable error message as to why. If it accepts the token, then it will be captured by the argument for later use by it's command.
Arguments also provide the ability to 'complete' a partial token. In some situations completions are not possible or do not make sense, but in many situations completions can be very helpful and save on typing, reduce errors, and even provide a little help if there are alot of options. The more characters there are in the token, the narrower the list of completions becomes. If the argument supplies only a single completion, this completion will be filled in for the user. This is a very powerful capability that can be used to great effect!
Using arguments
Before writing a command, it is important to consult the various specifications that many commands may have. Once you have an idea of the arguments you will need for the command, and you have a syntax put together, you can begin by adding your arguments to the command.
Along with the label that was discussed earlier, commands also take a set of flags. A set of flags is supplied by the Argument class, but individual Argument types may also supply their own specific flags. At the end of this document will be a list of known flags and their purpose, but for now we will discuss the common Argument flags.
- SINGLE and MULTIPLE
-
By default arguments are 'SINGLE'. This means that the argument may only contain one value. In order to change this, and allow the argument to capture multiple values, you must set the MULTIPLE flag.
- OPTIONAL and MANDATORY
-
By default arguments are 'OPTIONAL'. This means that if the argument is not populated with any values, it will not be considered an error. In order to have the parser fail if the argument is not populated with at least one value, set the MANDATORY flag.
- EXISTING and NONEXISTENT
-
These flags are not used by all arguments and may be used to alter the behavior of 'accept' and 'complete' depending on the argument, and their values. As an example, the FileArgument by default will accept most any string that denotes a legal file name. In order to force it to only accept tokens that denote an existing file on the file system than set the EXISTING flag. In order to force it to only accept tokens that denote a file that does not exist already, set the NONEXISTENT flag.
Most arguments have overloaded constructors that allow you to not set any flags. If no such constructor exists, then feel free to create one! Optionally, it is safe to provide '0'(zero) for the flags parameter to mean no flags.
Once you have created the arguments that your command will need, you need to 'register' the arguments. This needs to be done in the Command constructor. Each argument needs to be passed to the registerArguments(Argument...) method. Once this is done, your arguments are ready to be populated the syntax parser.
(Note: Arguments that have been registered, but do not have a matching syntax node with its label will not cause an error at runtime. But they do make trouble for the 'help' command. For this reason it is recommended to not register arguments that have not yet been mapped in the syntax.)
Using arguments
When your command enters at the execute() method, the arguments will be populated with any values that were capture from the command line. For the most part, you will only need to be concerned with three methods supplied by Argument.
- public boolean isSet()
-
If the argument has accepted and captured a token, then this method will return true. Commands should always check this method before querying for the captured values. If you query an argument for its values when it has none, the behavior is undefined and the return value (or possible exception) is unspecified and subject to change without notice. (The one case where this is not totally true is when an argument has the MANDATORY flag, as in this case this will _always_ return true. Though it is still considered 'good practice' to check this method before querying for values)
- public V getValue()
-
This method returns the single value of an argument that was registered as SINGLE. If the argument has the MULTIPLE flag set, this method should not be used as it will throw an exception if there is more than one value captured by the argument. If there are no values captured, this currently returns null, but as noted earlier, this may not always be the case, and should not be relied upon.
- public V[] getValues()
-
This method returns the captured values as an array. Calling this method when there the SINGLE flag is set is perfectly acceptable. Though it is usually more convenient to use the getValue() method.
Thats about it for arguments. Simple huh? Arguments are designed to allow for rapid development of commands and as such provide a nice simple interface for using arguments 'out of the box' so to speak. But the real power of arguments are their ability to be extended and manipulated in many ways so as to provide a more feature filled command line interface.
Basic argument types
Here are a list of the more common argument types, along with a short description on their purpose, features and usage.
- AliasArgument
-
An argument that accepts an 'alias'. It provides completion against those aliases that have been registered via plugin descriptors, and may also include the bjorne-style aliases if the bjorne interpreter is in use. (I'm not sure if it currently does, if not it should!)
- FileArgument
-
An argument that accepts a java.io.File. As used in an example above, this argument is affected by the EXISTING and NONEXISTENT flags of Argument. FileArgument also currently provides two of its own flags that may be set. ALLOW_DODGY_NAMES is used to override the 'accept' and 'complete' features to allow filenames that begin with a '-'(hyphen). Normally FileArgument would consider such a filename to be an error, and reject such a token. There is also the HYPHEN_IS_SPECIAL flag, which allows a single '-' to be accepted. The purpose for this is to allow '-' to exist amongst a list of files, denoting stardnard input or output should be used instead. This feature is subject to change (pending some 'better way' of handling this).
- FlagArgument
-
This is likely to be the most used argument of all. It is used to denote a option that has no associated argument. This argument does not actually capture a token, instead it holds a single value of true if it has been found. This means that you can use isSet() to map its value to a local/instance boolean value. In some cases, a command may wish to allow a flag to be used multiple times to add advanced meaning. The command can use getValues().length in such a case to determine the number of times it has been specified.
- IntegerArgument / LongArgument / DecimalArgument(TODO)
-
Allows an integer value to be captured on the command line. These arguments do not provide very helpful completion, as their domain of completions is generally too large. Their main purpose is to parse valid integers, rejecting those that are malformed.
- StringArgument
-
This is one of the most 'accepting' arguments, as it will accept any token that is given to it. It also provides no completion. If your command really needs an unbounded String, then this is the right argument to use. This argument should be extended for cases where you want to accept a string, but the domain of acceptable strings is limited, and you wish to reject those tokens not within that domain and also possibly provide completion for the argument.
- URLArgument
-
Similar in some respects to FileArgument, the URLArgument accepts valid tokens that represent a URL. This argument also respects the EXISTING and NONEXISTENT flags. Completion for parts of a url (the scheme for example), may be able to complete, but actual URL completion of domain names and the like may be nearly impossible. It should also be noted that the EXISTING and NONEXISTENT flags will likely cause a DNS lookup to be performed,
Syntax - Defining Commands
The syntax of a command is the definition of options, symbols and arguments that are accepted by commands. Each command defines its own syntax, allowing customization of flags and parameters, as well as defining order. The syntax is constructed using several different mechanisms, which when combined, allow for a great deal of control in restricting what is acceptable in the command line for a given command.
How it works
When you define a new command, you must give define a syntax bundle within a syntax extension point. When the plugin is loaded, the syntax bundle is parsed from the descriptor and loaded into the syntax manager. When the bundle is needed, when completing or when preparing for execution, the bundle is retrieved. Because a syntax bundle is immutable, it can be cached completely, and used concurrently.
Also, the help system uses the syntax to create usage statements and to map short & long flags to the description from an argument.
The puzzle pieces
See this document page for a concise description of the various syntax elements.
When setting out to define the syntax for a command, it is helpful to layout the synopsis and options that the command will need. The synopsis of a command can be used to define separate modes of operation. The syntax block itself is an implied <alternatives>, which means if parsing one fails, the next will be tried. To give an example of how breaking down a command into multiple synopsis can be helpful, we'll setup the syntax for a hypothetical 'config' command that allows listing, setting and clearing of some system configurations.
First, our synopsis...
config
Lists all known configuration options and their values
config -l And our syntax...
<syntax alias="config">
<empty />
<option argLabel="list" shortName="l">
<sequence>
<option argLabel="set" shortName="s">
<argument argLabel="value">
</sequence>
<option argLabel="clear" shortName="c">
</syntax>
To be continued...Utility classes
The cli project contains a few utility classes to make implementation of common features across multiple commands easier. Because it is recommended that these classes be used when possible, they are quite well documented, and provide fairly specific information on their behavior, and how to use them. A brief outline will be provided here, along with links to the actual javadoc page.
AbstractDirectoryWalker
ADW is _the_ tool for doing recursive directory searches. It provides a Visitor pattern interface, with a set of specific callbacks for the implementor to use. It has many options for controlling what it returns, and with the right configuration, can be made to do very specific searching.
Control
The walker is mainly controlled by FileFilter instances. Multiple filters can be supplied, providing an implied '&&' between each filter. If any of the filters reject the file, then the extending class will not be asked to handle the file. This can be used to create very precise searches by combining multiple boolean filters with specific filter types.
The walker also provides the ability to filter files and directories based on a depth. When the minimum depth is set, files and directories below a given level will not be handled. The directories that are passed to walk() are considered to be at level 0. Therefore setting a min-depth of 0 will not pass those directories to the callbacks. When the maximum depth is set, directories that are at the maximum depth level will not be recursed into. They will however still be passed to the callbacks, pending acceptance by the filter set. Therefore setting a value of 0 to the max level may return the initial directories supplied to walk(), but it will not recurse into them.
Note: Boolean filters are not yet implemented, but they are on the short list.
Extending the walker
Although you can extend the walker to a class of it's own, the recommended design pattern is to implement the walker as a non-static inner class, or an anonymous inner class. This design gives the implemented callbacks of the walker access to the inner structure of the command it's used in. When the walker runs it will pass accepted files and directories to the appropriate callback methods. The walker also has callbacks for specific events, including the beginning and end of a walk, as well as when a SecurityException is encountered when attempting to access a file or directory.
- public abstract void handleFile(File)
-
Tells the implementing class that a regular file has been found and accepted.
- public abstract void handleDir(File)
-
Tells the implementing class that a directory has been found and accepted.
- public void handleSpecialFile(File)
-
Tells the implementing class that a file has been found that is neither a directory or a regular file.
- protected void handleRestrictedFile(File)
- Tells the implementing class that it has found a file that triggered a SecurityException. By default, this method throws an IOException. This will cause walking to completly halt, which is likely undesired, and so it is highly recommended to override this method to provide suitable error message, and optionally continue walking.
- protected void handleStartingDir(File)
-
Tells the implementing class that it is about to start walking the file system from the given file. This is triggered before the file itself is actually resolved. So the caller has a chance to do some initialization, like possibly changing the current working directory to make a relative path resolve with a different prefix path.
- protected void lastAction(boolean)
-
Tells the implementing class that walking has finished. If the walker stopped walking because it was requested to do so, then the boolean parameter will be true. Otherwise if the walker finished normally, it will be false.
Debugging
Debugging code running on the JNode platform is no easy task. The platform currently has none of the nice debugging support that you normally find on a mature Java platform; no breakpoints, no looking at object fields, stack frames, etc.
Instead, we typically have to resort to sending messages to the system Logger, adding traceprint statements and calling 'dumpStack' and 'printStackTrace'. Here are some other pointers:
- If you are debugging a JNode command, you may be able to use ShellEmu or TestHarness to run and debug JNode specific code in your development environment. (This may not work if your command makes use of JNode specific services.)
- A lot of classes have no JNode platform dependencies, and can be debugged using JUnit tests running in your development sandbox.
- If you are debugging low-level JNode code, you can use "Unsafe.debug(...)" calls and the (so called) Kernel debugger to get trace information without causing object allocation. This is particularly important when debugging the JNode memory management, etc where any object allocation could trigger a kernel panic.
- Beware of the effects of adding debug code on JNode system performance, and on timing related bugs; e.g. race conditions.
There is also a simple debugger that can be used in textmode to display threads and their stacktraces. Press Alt-SysRq to enter the debugger and another Alt-SysRq to exit the debugger. Inside the debugger, press 'h' for usage information.
Note: the Alt-SysRq debugger isn't working at the moment: see this issue.
Kernel debugger
A very simple kernel debugger has been added to the JNode nano-kernel. This debugger is able to send all data outputted to the console (using Unsafe.debug) to another computer via a null-modem cable connected to COM1.
From the other computer you can give simple commands to the debugger, such as dump the processor thread queues and print the current thread.
The kernel debugger can be enabled by adding " kdb" to the grub kernel command line, or by activating it in JNode using a newly added command: "kdb".
Ewout
Using "remoteout" to record console / logger output
The remoteout command allows you to send a copy of console output and logger output to a remote TCP or UDP receiver. This allows you to capture console output for bug reports, and in the cases where JNode is crashing.
Before you run the command, you need to set up a receiver application on the remote host to accept and record the output. More details (including a brief note on the JNode RemoteReceiver application) may be found in the remoteout command page. Please read the Bugs section as well!
Operating System
This part contains the technical documentation of the JNode Operating System.
Boot and startup
During the boot process of JNode, the kernel image is loaded by Grub and booted. After the bootstrapper code, we're running plain java code. The fist code executed is in org.jnode.boot.Main#vmMain() which initializes the JVM and starts the plugin system.
Driver framework
The basic device driver design involves 3 components:
- Device: a representation of the actual hardware device
- Driver: a software driver able to control a Device
- DeviceAPI: a programming interface for a Device, usually implemented by the Driver.
There is a DeviceManager where all devices are registered. It delegates to DeviceToDriverMapper instances to find a suitable driver for a given device. Instances of this mapper interface use e.g. the PCI id of a device (in case of PCIDevice) to find a suitable driver. This is configurable via a configuration file.
For a device to operate there are the following resources available:
- Hardware interrupts. A driver can register an IRQHandler which is called on its own (normal java-) thread. The native kernel signals a hardware interrupt by incrementing a counter for that interrupts, after which the thread scheduler dispatches such events to the correct threads of the IRQHandler's.
-
DMA channels. A driver can claim a DMA channel.
This channel can be setup, enabled and disabled. - IO port access. An Unsafe class has native methods for this. A device must first claim a range of IO ports before it can gain access to it.
- Memory access. A device can claim a range of the the memory addressspace. A MemoryResource is given to the device. The device can use the methods of the MemoryResource to actually access the memory.
Filesystem framework
The filesystem support in JNode is split up into a generic part and a filesystem specific part. The role of the generic part is:
- Keep track of all mounted filesystems.
- Map between path names are filesystem entries.
- Share filesystem entries between various threads/processes.
The role of the filesystem specific part is:
- Store and retrieve files.
- Store and retrieve directories.
We should be more specific about what a filesystem is. JNode makes a distinction the a FileSystemType and a FileSystem. A FileSystemType has a name, can detect filesystems of its own type on a device and can create FileSystem instances for a specific device (usually a disk). A FileSystem implements storing/retrieving files and directories.
To access files in JNode, use the regular classes in the java.io package. They are connected to the JNode filesystem implementation. A direct connection to the filesystem implementation is not allowed.
FrameBuffer devices
This chapter details the FrameBuffer device design and the interfaces involved in the design.
FrameBufferAPI
All framebuffer devices must implement this API.
FrameBufferConfiguration
TODO write me.
Surface
TODO write me.
HardwareCursorAPI
TODO write me.
DisplayDataChannelAPI
TODO write me.
Network devices
This chapter details the design of network devices and describe the interfaces involved.
NetDeviceAPI
Every network device must implement this API.
The API contains methods to get the hardware address of the device, send data through the device and get/set protocol address information.
When a network deivce receives data, it must deliver that data to the NetworkLayerManager. The AbstractNetworkDriver class (which is usually the baseclass for all network drivers) contains a helper method (onReceive) for this purpose.
Network protocols
This chapter will detail the interfaces involved in the network protocol layer.
NetworkLayer
This interface must be implemented by all network protocol handlers.
TransportLayer
This interface must be implemented by OSI transport layer protocols.
LinkLayer
This interface must be implemented by OSI link layer protocols.
Registration
To register a network layer, the network layer class must be specified in an extension of the "org.jnode.net.networkLayers" extension point.
This is usually done in the descriptor of the plugin that holds the network layer.
Architecture specifics
This chapter contains the specific technical operating system details about the various architectures that JNode is operating on.
X86 Architecture
The X86 architecture is targets the Intel IA32 architecture implemented by the Intel Pentium (and up) processors and the AMD Athlon/Duron (etc) processors.
Physical memory layout
This architecture uses a physical memory layout as given in the picture below.

Shell
The new command line syntax mechanism
In the classical Java world, a command line application is launched by calling the "main" entry point method on a nominated class, passing the user's command arguments as an array of Strings. The command is responsible for working out which arguments represent options, which represent parameters and so on. While there are (non-Sun) libraries to help with this task (like the Java version of GNU getOpts), they are rather primitive.
In JNode, we take a more sophisticated approach to the issue of command arguments. A native JNode command specifies its formal arguments and command line syntax. The task of matching actual command line arguments is performed by JNode library classes. This approach offers a number of advantages over the classical Java approach:
- The application programmer has less work to do.
- The user sees more uniform command syntax.
- Diagnostics for incorrect command arguments can be more uniform.
In addition, this approach allows us to do some things at the Shell level that are difficult with (for example) UNIX style shells.
- The JNode shell does intelligent command line completion based on a command's declared syntax and argument types. For example, if the syntax requires a device name at the cursor position when the user hits TAB, the JNode shell will complete against the device namespace.
- The JNode help command uses a command's declared syntax to produce accurate "usage" and parameter type descriptions. These can be augmented by descriptions embedded in the syntax, or in separate files.
- In the new version of the JNode syntax mechanisms, command syntaxes are specified in XML separate from the Java source code. Users can tailor the command syntax, like UNIX aliases only better. This can be used to support portable scripting; e.g. Unix-like command syntaxes could be used with a POSIX shell compatible interpreter to run Unix shell scripts.
As the above suggests, there are two versions of JNode command syntax and associated mechanisms; i.e parsing, completion, help and so on. In the first version (the "old" mechanisms) the application class declares a static Argument object for each formal parameter, and creates a static "Help.Info" data structure containing Syntax objects that reference the Arguments. The command line parser and completer traverse the data structures, binding values to the Arguments.
The problems with the "old" mechanisms include:
- Use of statics to hold the Argument and Help.Info objects makes JNode commands non-reentrant, leading to unpredictable results when a command is executed in two threads.
- The Syntax, Argument and associated classes were never properly documented, making them hard to maintain and hard to use.
- There were numerous bugs and implementation issues; e.g. Unix-style named options didn't work, completion didn't work properly with alternative syntaxes, and so on.
- Command syntaxes could not be tailored, as described above.
The second version (the "new" mechanisms) are a ground-up redesign and reimplementation:
- Argument objects are created by the command class constructor, and registered to form an ArgumentBundle. Thus, command syntax is not an impediment to making command classes re-entrant.
- Syntax objects are created from XML that is defined in the command's plugin descriptor, and that can be overridden from the JNode shell using the "syntax" command.
- The "new" Syntax classes are much richer than the "old" versions. Each Syntax class has a "prepare" method that emits a simple BNF-like grammar; i.e. the MuSyntax classes. This grammar is used by the MuParser which performs n-level backtracking, and supports "normal" and "completion" modes. (Completion mode parsing works by capturing completions at the appropriate point and then initialing backtracking to find other alternatives.)
A worked example: the Cat command.
(This example is based on material provided by gchii)
The cat command is a JNode file system command for the concatenation of files.
The alternative command line syntaxes for the command are as follows:
cat cat -u | -urls <url> ... | cat <file> ...
The simplest use of cat is to copy a file to standard output displaying the contents of a file; for example.
cat d.txt
The following example displays a.txt, followed by b.txt and then c.txt.
cat a.txt b.txt c.txt
The following example concatenates a.txt, b.txt and c.txt, writing the resulting file to d.txt.
cat a.txt b.txt c.txt > d.txt
In fact, the > output redirection in the example above is performed by the command shell and interpreter, and the "> d.txt" arguments are removed before the command arguments are processed. As far the command class is concerned, this is equivalent to the previous example.
Finally, the following example displays the raw HTML for the JNode home page:
cat --urls http ://www.jnode.org/
Syntax specification
The syntax for the cat command is defined in fs/descriptors/org.jnode.fs.command.xml.
The relevant section of the document is as follows:
39 <extension point="org.jnode.shell.syntaxes"> 40 <syntax alias="cat"> 41 <empty description="copy standard input to standard output"/> 42 <sequence description="fetch and concatenate urls to standard output"> 43 <option argLabel="urls" shortName="u" longName="urls"/> 44 <repeat minCount="1"> 45 <argument argLabel="url"/> 46 </repeat> 47 </sequence> 48 <repeat minCount="1" description="concatenate files to standard output"> 49 <argument argLabel="file"/> 50 </repeat> 51 </syntax>
Line 39: "org.jnode.shell.syntaxes" is an extension point for command syntax.
Line 40: The syntax entity represents the entire syntax for a command. The alias attribute is required and associates a syntax with a command.
Line 41: When parsing a command line, the empty tag does not consume arguments. This is a description of the cat command.
Line 42: A sequence tag represents a group of options and arguments, and others.
Line 43: An option tag is a command line option, such as -u and --urls. Since -u and --urls are actually one and the same option, the argLable attribute identifies an option internally.
Line 44: An option might be used more than once on a command line. When minCount is one or more, an option is required.
Line 45: An argument tag consumes one command line argument.
Line 48: When minCount is 1, an option is required.
Line 49: An argument tag consumes one command line argument.
The cat command is implemented in CatCommand.java. The salient parts of the command's implementation are as follows.
54 private final FileArgument ARG_FILE =
55 new FileArgument("file", Argument.OPTIONAL | Argument.MULTIPLE,
56 "the files to be concatenated");
This declares a formal argument to capture JNode file/directory pathnames from the command line; see the specification of the org.jnode.shell.syntax.FileArgument. The "Argument.OPTIONAL | Argument.MULTIPLE" parameter gives the argument flags. Argument.OPTIONAL means that this argument may be optional in the syntax. The Argument.MULTIPLE means that the argument may be repeated in the syntax. Finally, the "file" label matches the "file" attribute in the XML above at line 49.
58 private final URLArgument ARG_URL =
59 new URLArgument("url", Argument.OPTIONAL | Argument.MULTIPLE,
60 "the urls to be concatenated");
This declares a formal argument to capture URLs from the command line. This matches the "url" attribute in the XML above at line 45.
62 private final FlagArgument FLAG_URLS =
63 new FlagArgument("urls", Argument.OPTIONAL, "If set, arguments will be urls");
This declares a formal flag that matches the "urls" attribute in the XML above at line 43.
67 public CatCommand() {
68 super("Concatenate the contents of files, urls or standard input to standard output");
69 registerArguments(ARG_FILE, ARG_URL, FLAG_URLS);
70 }
The constructor for the CatCommand registers the three formal arguments, ARG_FILE, ARG_URL and FLAG_URLS. The registerArguments() method is implemented in AbstractCommand.java. It simply adds the formal arguments to the command's ArgumentBundle, making them available to the syntax mechanism.
79 public void execute() throws IOException {
80 this.err = getError().getPrintWriter();
81 OutputStream out = getOutput().getOutputStream();
82 File[] files = ARG_FILE.getValues();
83 URL[] urls = ARG_URL.getValues();
84
85 boolean ok = true;
86 if (urls != null && urls.length > 0) {
87 for (URL url : urls) {
...
107 } else if (files != null && files.length > 0) {
108 for (File file : files) {
...
127 } else {
128 process(getInput().getInputStream(), out);
129 }
130 out.flush();
131 if (!ok) {
132 exit(1);
133 }
134 }
The "execute" method is called after the syntax processing has occurred, and after the command argument values have been converted to the relevant Java types and bound to the formals. As the code above shows, the method uses a method on the formal argument to retrieve the actual values. Other methods implemented by AbstractCommand allow the "execute" to access the command's standard input, output and error streams as Stream objects or Reader/Writer objects, and to set the command's return code.
Note: ideally the syntax of the JNode cat command should include this alternative:
cat ( ( -u | -urls <url> ) | <file> ) ...
or even this:
cat ( <url> | <file> ) ...
allowing <file> and <url> arguments to be interspersed. The problem with the first alternative syntax above is that the Argument objects do not allow the syntax to capture the complete order of the interspersed <file> and <url> arguments. In order to support this, we would need to replace ARG_FILE and ARG_URL with a suitably defined ARG_FILE_OR_URL. The problem with the second alternative syntax above is some legal <url> values are also legal <file> values, and the syntax does not allow the user to control the disambiguation.
For more information, see also org.jnode.fs.command.xml - http://jnode.svn.sourceforge.net/viewvc/jnode/trunk/fs/descriptors/org.j... .
CatCommand.java - http://jnode.svn.sourceforge.net/viewvc/jnode/trunk/fs/src/fs/org/jnode/...
Ideas for future Syntax enhancements
Here are some ideas for work to be done in this area:
- Extend OptionSetSyntax to support "--" as meaning everything after here is not an option.
- Make OptionSetSyntax smarter in its handling of repeated options. For example completing "cp --recursive " should not offer "--recursive" as a completion.
- Improve "help", including improving the output, incorporating more descriptions from the syntax, in preference to descriptions from the Command class, and supporting multi-lingual descriptions. (In fact, we need to go a lot further ... including supporting full documentation complete with a way to specify markup and cross-references. But that's a different problem really.)
- Extend the Argument APIs so that we can specify (for example) that a FileArgument should match an existing file, an existing directory, a path to an object that does not exist, etc. This potentially applies to all name arguments over dynamic namespaces.
- Extend the Argument APIs to support expansion of patterns against the FS and other namespaces. This needs to be done in a way that allows the user, shell and command to control whether or not expansion occurs. We don't want commands to have to understand that there are patterns at all .... except in cases where the command needs to know (e.g. some flavours of rename command). And we also need to cater for shell languages (e.g. UNIX derived ones) where FS pattern expansion is clearly a shell responsibility.
- Add support for command-specific Syntax classes; e.g. to support complex command syntaxes like UNIX style "expr" and "test" commands.
- Add command syntax support for command-line interactive commands like old-school UNIX ftp and nslookup. (In JNode, we already have a tftp client that runs this way.)
- Implement a compatibility library to allow JNode commands to be executed in the class Java world.
JNode Command and Syntax APIs
This page is an overview of the JNode APIs that are involved in the new syntax mechanisms. For more nitty-gritty details, please refer to the relevant javadocs.
Note:
- These APIs still change a bit from time to time. (But if your code is in the JNode code base, you won't need to deal with these changes.)
- The javadocs on the JNode website currently do not include the "shell" APIs.
You can generate the javadocs in a JNode build sandbox by running "./build.sh javadoc". - If the javadocs are inadequate, please let us know via a JNode "bug" request.
Java package structure
The following classes mostly reside in the "org.jnode.shell.syntax" package. The exceptions are "Command" and "AbstractCommand" which live in "org.jnode.shell". (Similarly named classes in the "org.jnode.shell.help" and "org.jnode.shell.help.args" packages are part of the old-style syntax support.)
Command
The JNode command shell (or more accurately, the command invokers) understand two entry points for launching classes as "commands". The first entry point is the "public static void main(String[])" entry point used by classic Java command line applications. When a command class has (just) a "main" method, the shell will launch it by calling the method, passing the command arguments. What happens next is up to the command class:
- A non-JNode application will typically deal with the command arguments itself, or using some third party class like "gnu.getopt.GetOpt".
- A JNode-aware application can also use the old-style syntax method directly, by calling a "Help.Info" object's "parse(String[])" method on the argument strings.
The preferred entry point for a JNode command class is the "Command.execute(CommandLine, InputStream, PrintStream, PrintStream)" method. On the face of it, this entry point offers a number of advantages over the "main" entry point:
- The "execute" method provides command's IO streams explicitly, rather than relying on the "System.{in,out,err}" statics. (Those statics are problematic, unless you are using proclets or isolates.)
- The "execute" method gives the application access to more information gleaned from the command line; e.g. the command name (alias) supplied by the user.
Unless you are using the "default" command invoker, a command class with an "execute" entry point will be invoked via that entry point, even it it also has a "main" entry point. What happens next is up to the command class:
- The "execute" method may fetch the user's argument strings from the CommandLine object and do its own argument analysis.
- If the command class is designed to use old-style syntax mechanisms, the "execute" method will typically call the "parse(String[])" method and proceed as described above.
- If the command class is designed to use new-style syntax mechanisms, argument analysis will already have been done. This can only happen if the command class extends the AbstractCommand class; see below.
AbstractCommand
The AbstractCommand class is a base class for JNode-aware command classes. For command classes that do their own argument processing, or that use the old-stle syntax mechanisms, use of this class is optional. For commands that want to use the new-style syntax mechanisms, the command class must be a direct or indirect subclass of AbstractCommand.
The AbstractCommand class provides helper methods useful to all command class.
- The "exit(int)" method can be called from the command thread terminate command execution with an return code. This is roughly equivalent to a classic Java application calling "System.exit(int)".
- The "getInput()", "getOutput()", "getError()" and "getIO(int)" methods return "CommandIO" instances that can be used to get a command's "standard io" streams as
Java Input/OutputStream or Reader/Writer objects.
The "getCommandLine" method returns a CommandLine instance that holds the command's command name and unparsed arguments.
But more importantly, the AbstractCommand class provides infrastructure that is key to the new-style syntax mechanism. Specifically, the AbstractCommand maintains an ArgumentBundle for each command instance. The ArgumentBundle is created when either of the following happens:
- The child class constructor chains the AbstractCommand(String) constructor. In this case an (initially) empty ArgumentBundle is created.
- The child class constructor calls the "registerArgument(Argument ...)" method. In this case, an ArgumentBundle is created (if necessary) and the arguments are added to it.
If it was created, the ArgumentBundle is populated with argument values before the "execute" method is called. The existence of an ArgumentBundle determines whether the shell uses old-style or new-style syntax, for command execution and completion. (Don't try to mix the two mechanisms: it is liable to lead to inconsistent command behavior.)
Finally, the AbstractCommand class provides an "execute(String[])" method. This is intended to provide a bridge between the "main" and "execute" entry points for situations where a JNode-aware command class has to be executed via the former entry point. The "main" method should be implemented as follows:
public static void main(String[] args) throws Exception {
new XxxClass().execute(args);
}
CommandIO and its implementation classes
The CommandIO interfaces and its implementation classes allow commands to obtain "standard io" streams without knowing whether the underlying data streams are byte or character oriented. This API also manages the creation of 'print' wrappers.
Argument and sub-classes
The Argument classes play a central place in the new syntax mechanism. As we have seen above, the a command class creates Argument instances to act as value holders for its formal arguments, and adds them to its ArgumentBundle. When the argument parser is invoked, traverses the command syntax and binds values to the Arguments in the bundle. When the command's "execute" entry point is called, the it can access the values bound to the Arguments.
The most important methods in the Argument API are as follows:
- The "accept(Token)" method is called by the parser when it has a candidate token for the Argument. If the supplied Token is acceptable, the Argument uses "addValue(...)" to add the Token to its collection. If it is not acceptable, "SyntaxErrorException" is thrown.
- The "doAccept(Token)" abstract method is called by "accept" after it has done the multiplicity checks. It is required to either return a non-null value, or throw an exception; typically SyntaxErrorException.
- In completion mode, the parser calls the "complete(...)" method to get Argument specific completions for a partial argument. The "complete" method is supplied a CompletionInfo object, and should use it to record any completions.
- The "isSet()", "getValue()" and "getValues()" methods are called by a command class to obtain the value of values bouond to an Argument.
The constructors for the descendent classes of Argument provide the following common parameters:
- The "label" parameter provides a name for the Attribute that is used to bind the Argument to Syntax elements. It must be unique in the context of the command's ArgumentBundle.
- The "flags" parameter specify the Argument's multiplicity; i.e how many values are allowed or required for the Argument. The allowed flag values are defined in the Argument class. A well-formed "flags" parameter consists of OPTIONAL or MANDATORY "or-ed" with SINGLE or MULTIPLE.
- The "description" parameter gives a default description for the Argument that can be used in "help" messages.
The descendent classes of Argument correspond to different kinds of argument. For example:
- StringArgument accepts any String value,
- IntegerArgument accepts and (in some cases) completes an Integer value,
- FileArgument accepts a pathname argument and completes it against paths for existing objects in the file system, and
- DeviceArgument accepts a device name and completes it against the registered device names.
There are two abstract sub-classes of Argument:
- EnumArgument accepts values for a given Java enum.
- MappedArgument accepts values based on a String to value mapping supplied as a Java Map.
Please refer to the javadoc for an up-to-date list of the Argument classes.
Syntax and sub-classes
As we have seen above, Argument instances are used to specify the command class'es argument requirements. These Arguments correspond to nodes in one or more syntaxes for the command. These syntaxes are represented in memory by the Syntax classes.
A typical command class does not see Syntax objects. They are typically created by loading XML (as specified here), and are used by various components of the shell. As such, the APIs need not concern the application developer.
ArgumentBundle
This class is largely internal, and a JNode application programmer doesn't need to access it directly. Its purpose is to act as the container for the new-style Argument instances that belong to a command class instance.
MuSyntax and sub-classes
The MuSyntax class and its subclasses represent the BNF-like syntax graphs that the command argument parser actually operate on. These graphs are created by the "prepare" method of new-style Syntax objects, in two stages. The first stage is to build a tree of MuSyntax objects, using symbolic references to represent cycles. The second stage is to traverse the tree, replacing the symbolic references with their referents.
There are currently 6 kinds of MuSyntax node:
- MuSymbol - this denotes a symbol (keyword) in the syntax. When a MuSymbol is match, no argument capture takes place.
- MuArgument - this denotes a placeholder for an Argument in the syntax. When a MuArgument is encountered, the corresponding Argument's "accept" method is called to see if the current token is acceptable. If it is, the token is bound to the Argument; otherwise the parser starts backtracking.
- MuPreset - this is a variation on a MuArgument in which a "preset" token is passed to the Argument. Unlike MuArgument and MuSymbol, a MuPreset does not cause the parser to advance to the next token.
- MuSequence - this denotes that a list of child MuSyntax nodes must be matches in a given sequence.
- MuAlternation - this denotes that a list of child MuSyntax nodes must be tried one at a time in a given order.
- MuBackReference - this denotes a reference to an ancestor node in the MuSyntax tree. These nodes are replaced with their referents before parsing takes place.
MuParser
The MuParser class does the real work of command line parsing. The "parse" method takes input parameters that provide a MuSyntax graph, a TokenSource and some control parameters.
The parser maintains three stacks:
- The "syntaxStack" holds the current "productions" waiting to be matched against the token stream.
- The "choicePointStack" holds "choicePoint" objects that represent alternates that the parser hasn't tried yet. The choicepoints also record the state of the "syntaxStack" when the alternation was encountered, and top of the "argsModified" stack.
- The "argsModified" stack keeps track of the Arguments that need to be "unbound" when the parser backtracks.
In normal parsing mode, the "parse" method matches tokens until either the parse is complete, or an error occurs. The parse is complete if the parser reaches the end of the token stream and discovers that the syntax stack is also empty. The "parse" method then returns, leaving the Arguments bound to the relevant source tokens. The error case occurs when a MuSyntax does not match the current token, or the parser reaches the end of the TokenSource when there are still unmached MuSyntaxes on the syntax stack. In this case, the parser backtracks to the last "choicepoint" and then resumes parsing with the next alternative. If no choicepoints are left, the parse fails.
In completion mode, the "parse" method behaves differently when it encounters the end of the TokenSource. The first thing it does is to attempt to capture a completion; e.g. by calling the current Argument's "complete(...)" method. Then itstarts backtracking to find more completions. As a result, a completion parse may do a lot more work than a normal parse.
The astute reader may be wondering what happens if the "MuParser.parse" method is applied to a pathological MuSyntax; e.g. one which loops for ever, or that requires exponential backtracking. The answer is that the "parse" method has a "stepLimit" parameter that places an upper limit on the number of main loop iterations that the parser will perform. This indirectly addresses the issue of space usage as well, though we could probably improve on this. (In theory, we could analyse the MuSyntax for common pathologies, but this would degrade parser performance for non-pathological MuSyntaxes. Besides, we are not (currently) allowing applications to supply MuSyntax graphs directly, so all we really need to do is ensure that the Syntax classes generate well-behaved MuSyntax graphs.)
Syntax and XML syntax specifications
As the parent page describes, the command syntax "picture" has two distinct parts. A command class registers Argument objects with the infrastructure to specify its formal command parameters. The concrete syntax for the command line is represented in memory by Syntax objects.
This page documents the syntactic constructs provided by the Syntax objects, and the XML syntax that provides the normal way of specifying a syntax.
You will notice that there can be a number of ways to build a command syntax from the constructs provided. This is redundancy is intentional.
The Syntax base class
The Syntax class is the abstract base class for all classes that represent high-level syntactic constructs in the "new" syntax mechanisms. A Syntax object has two (optional) attributes that are relevant to the process of specifying syntax:
- The "label" attribute gives a name for the syntax node that will be used when the node is formatted; e.g. for "help" messages.
- The "description" attribute gives a basic description for the syntax node.
These attributes are represented in an XML syntax element using optional XML attributes named "label" and "description" respectively.
ArgumentSyntax
An ArgumentSyntax captures one value for an Argument with a given argument label. Specifically, an ArgumentSyntax instance will cause the parser to consume one token, and to attempt to bind it to the Argument with the specified argument label in the current ArgumentBundle.
Note that many Arguments are very non-selective in the tokens that they will match. For example, while an IntegerArgument will accept "123" as valid, so will "FileArgument" and many other Argument classes. It is therefore important to take account the parser's handling of ambiguity when designing command syntaxes; see below.
Here are some ArgumentSyntax instances, as specified in XML:
<argument argLabel="foo">
<argument label="foo" description="this controls the command's fooing" argLabel="foo">
An EmptySyntax matches absolutely nothing. It is typically used when a command requires no arguments.
<empty description="dir with no arguments lists the current directory">
OptionSyntax
An OptionSyntax also captures a value for an Argument, but it requires the value token to be preceded by a token that gives an option "name". The OptionSyntax class supports both short option names (e.g. "-f filename") and long option names (e.g. "--file filename"), depending on the constructor parameters.
<option argLabel="filename" shortName="f">
<option argLabel="filename" longName="file">
<option argLabel="filename" shortName="f" longName="file">
If the Argument denoted by the "argLabel" is a FlagArgument, the OptionSyntax matches just an option name (short or long depending on the attributes).
SymbolSyntax
A SymbolSyntax matches a single token from the command line without capturing any Argument value.
<symbol symbol="subcommand1">
VerbSyntax
A VerbSyntax matches a single token from the command line, setting an associated Argument's value to "true".
<verb symbol="subcommand1" argLabel="someArg">
SequenceSyntax
A SequenceSyntax matches a list of child Syntaxes in the order specified.
<sequence description="the input and output files">
<argument argLabel="input"/>
<argument argLabel="output"/>
</sequence>
AlternativesSyntax
An AlternativesSyntax matches one of a list of alternative child Syntaxes. The child syntaxes are tried one at a time in the order specified until one is found that matches the tokens.
<alternatives description="specify an input or output file">
<option shortName="i" argLabel="input"/>
<option shortName="o" argLabel="output"/>
</alternatives>
RepeatSyntax
A RepeatSyntax matches a single child Syntax repeated a number of times. By default, any number of matches (including zero) will satisfy a RepeatSyntax. The number of required and allowed repetitions can be constrained using the "minCount" and "maxCount" attributes. The default behavior is to match lazily; i.e. to match as few instances of the child syntax as is possible. Setting the attribute eager="true" causes the powerset to match as many child instances as possible, within the constraints of the "minCount" and "maxCount" attributes.
<repeat description="zero or more files">
<argument argLabel="file"/>
</repeat>
<repeat minCount="1" description="one or more files">
<argument argLabel="file"/>
</repeat>
<repeat maxCount="5" eager="true"
description="as many files as possible, up to 5">
<argument argLabel="file"/>
</repeat>
OptionalSyntax
An OptionalSyntax optionally matches a sequence of child Syntaxes; i.e. it matches nothing or the sequence. The default behavior is to match lazily; i.e. to try the "nothing" case first. Setting the attribute eager="true" causes the "nothing" case to be tried second.
<optional description="nothing, or an input file and an output file">
<argument argLabel="input"/>
<argument argLabel="output"/>
</optional>
<optional eager="true"
description="an input file and an output file, or nothing">
<argument argLabel="input"/>
<argument argLabel="output"/>
</optional>
PowerSetSyntax
A PowerSetSyntax takes a list of child Syntaxes and matches any number of each of them in any order or any interleaving. The default behavior is to match lazily; i.e. to match as few instances of the child syntax as is possible. Setting the attribute eager="true" causes the powerset to match as many child instances as possible.
<powerSet description="any number of inputs and outputs">
<option argLabel="input" shortName="i"/>
<option argLabel="output" shortName="o"/>
</powerSet>
OptionSetSyntax
An OptionSetSyntax is like a PowerSetSyntax with the restriction that the child syntaxes must all be OptionSyntax instances. But what OptionSetSyntax different is that it allows options for FlagArguments to be combined in the classic Unix idiom; i.e. "-a -b" can be written as "-ab".
<optionSet description="flags and value options">
<option argLabel="flagOne" shortName="1"/>
<option argLabel="flagTwo" shortName="2"/>
<option argLabel="argThree" shortName="3"/>
</optionSet>
Assuming that the "flagOne" and "flagTwo" correspond to FlagArguments, and "argThree" corresponds to (say) a FileArgument, the above syntax will match any of the following: "-1 -2 -3 three", "-12 -3 three", "-1 -3 three -1", "-3 three" or even an empty argument list.
The <syntax ... > element
The outermost element of an XML Syntax specification is the <syntax> element. This element has a mandatory "alias" attribute which associates the syntax with an alias that is in force for the shell. The actual syntax is given by the <syntax> element's zero or more child elements. These must be XML elements representing Syntax sub-class instances, as described above. Conceptually, each of the child elements represents an alternative syntax for the command denoted by the alias.
Here are some examples of complete syntaxes:
<syntax alias="cpuid">
<empty description="output the computer's id">
</syntax>
<syntax alias="dir">
<empty description="list the current directory"/>
<argument argLabel="directory" description="list the given directory"/>
</syntax>
Ambiguous Syntax specifications
If you have implemented a language grammar using a parser generator (like Yacc, Bison, AntLR and so on), we will recall how the parser generator could be very picky about your input grammar. For example, these tools will often complain about "shift-reduce" or "reduce-reduce" conflicts. This is a parser generator's way of saying that the grammar appears (to it) to be ambiguous.
The new-style command syntax parser takes a different approach. Basically, it does not care if a command syntax supports multiple interpretations of a command line. Instead, it uses a simple runtime strategy to resolve ambiguity: the first complete parse "wins".
Since the syntax mechanisms don't detect ambiguity, it is up to the syntax designer to be aware of the issue, and take it into account when designing the syntax. Here is an example:
<alternatives>
<argument argLabel="number">
<argument argLabel="file">
</alternatives>
Assuming that "number" refers to an IntegerArgument, and "file" refers to a FileArgument, the syntax above is actually ambiguous. For example, a parser could in theory bind "123" to the IntegerArgument or the FileArgument. In practice, the new-style command argument parser will pick the first alternative that gives a complete parse, and bind "123" to the IntegerArgument. If you (the syntax designer) don't want this (e.g. because you want the command to work for all legal filenames), you will need to use OptionSyntax or TokenSyntax or something else to allow the end user to force a particular interpretation.
SyntaxSpecLoader and friends
More about the Syntax base class.
If you are planning on defining new sub-classes of Syntax, the two key behavioral methods that must be implemented are as follows:
- The "prepare" method is responsible for translating the syntax node into the MuSyntax graph that will be used by the parser. This will typically be produced by preparing any child syntaxes, and assembling them using the appropriate MuSyntax constructors. If the syntax entails recursion at the MuSyntax levels, this will initially be expressed using MuBackReferences. The recursion points will then transformed into graph cycles by calling "MuSyntax.resolveBackReferences()".
Another technique that can be used is to introduce "synthetic" Argument nodes with special semantics. For example, the OptionSetSyntax uses a special Argument class to deal with combined short options; e.g. where "-a -b" is expressed as "-ab". - The "format" method renders the Syntax in a form that is suitable for "usage" messages.
- The "toXML" method creates a "nanoxml.XMLElement" that expresses this Syntax node in XML form. It is used by the "SyntaxCommand" class when it dumps an syntax specification as text. It is important that "toXML" produces XML that is compatible with the SyntaxSpecLoader class; see below.
Using Command Line Completion (old syntax mechanism)
Note: this page describes the old syntax mechanism which is currently being phased out. Please refer to the parent menu for the pages on the new syntax mechanism.
The JNode Command Line Completion is one of the central aspects of the shell. JNode makes use of a sophisticated object model to declare command line arguments. This also provides for a standard way to extract a help-document that can be viewed by the user in different ways. Additionally, the very same object model can be used to access the arguments in a convenient manner, instead of doing the 133735th command line parsing implementation in computer history.
The following terms play an important role in this architecture:
- Parameter
A key that can be passed to a programm. Typically, this are command line switches like "-h" or "--help", or indicators for the type of the assigned argument. - Argument
A value that can be passed to a program. This can be filenames, free texts, integers or whatever type of arguments the program needs. - Syntax
A program can define multiple Syntaxes, which provide for structurally different tasks it can handle. A Syntax is defined as a collection of mandatory and optional Parameters.
A sample command
The command used in this document is a ZIP-like command. I will call it sip. It provides for a variety of different parameter types and syntaxes.
The sip command,in this example, will have the following syntaxes:
sip -c [-password <password>] [-r] <sipfile> [<file> ...]
sip -x [-password <password>] <sipfile> [<file> ...]
Named Parameters:
- -c: compress directory contents to a sipfile
- -x: extract a sipfile
- -r: recurse through subdirectories
Arguments:
- password: the password for the sipfile
- sipfile: the sipfile to perform the operation on
- file: if given, only includes the files in this list
Declaring Arguments and Parameters
Let's set some preconditions, which will be of importance in the following chapters.
- we will put the command into the package org.jnode.tools.command
- the actual java implementation of the packager are found in org.jnode.tools.sip
Therefore, the first lines of out Command class look like this:
package org.jnode.tools.command;
import org.jnode.tools.sip.*;
import org.jnode.shell.Command;
import org.jnode.shell.CommandLine;
import org.jnode.shell.help.*;
public class SipCommand implements Command{
After importing the necessary packages, let's dive into the declaration of the Arguments. This is almost necessarily the first step when you want to reuse arguments. Good practise is to always follow this pattern, so you don't have to completely rework the declaration sometime. In short, we will work above definition from bottom up.
You will note that all Arguments, Parameters and Syntaxes will be declared as static. This is needed because of the inner workings of the Command Line Completion, which has to have access to a static HELP_INFO field providing all necessary informations.
static StringArgument ARG_PASSWORD = new StringArgument("password", "the password for the sipfile");
static FileArgument ARG_SIPFILE = new FileArgument("sipfile", "the sipfile to perform the operation on");
static FileArgument ARG_FILE = new FileArgument("file", "if given, only includes the files in this list", Argument.MULTI);
Now we can declare the Parameters, beginning with the ones taking no Arguments.
Note: all Parameters are optional by default!
// Those two are mandatory, as we will define the two distinct syntaxes given above
static Parameter PARAM_COMPRESS = new Parameter(
"c", "compress directory contents to a sipfile", Parameter.MANDATORY);
static Parameter PARAM_EXTRACT = new Parameter(
"x", "extract a sipfile", Parameter.MANDATORY);
static Parameter PARAM_RECURSE = new Parameter(
"r", "recurse through subdirectories");
static Parameter PARAM_PASSWORD = new Parameter(
"password", "use a password to en-/decrypt the file", ARG_PASSWORD);
// here come our two anonymous Parameters used to pass the files
static Parameter PARAM_SIPFILE = new Parameter(
ARG_SIPFILE, Parameter.MANDATORY);
static Parameter PARAM_FILE = new Parameter(
ARG_FILE);
Wait!
There is something special about the second Syntax, the extract one. The command line completion for this one will fail, as it will try to suggest files that are in the current directory, not in the sipfile we want to extract from. We will need a special type of Argument to provide a convenient completion, along with an extra Parameter which uses it.
Test frameworks
Whenever you add some new functionality to JNode, please considering implementing some test code to exercise it.
Your options include:
- implementing JUnit tests for exercising self-contained JNode-specific library classes,
- implementing Mauve tests for JNode implementations of standard library classes,
- implementing black-box command tests using the org.jnode.test.harness.* framework, or
- implementing ad-hoc test classes.
We have a long term goal to be able to run all tests automatically on the new test server. New tests should be written with this in mind.
Black-box command tests with TestHarness
Overview
This page gives some guidelines for specifying "black-box tests" to be run using the TestHarness class; see Running black-box tests".
A typical black-box test runs a JNode command or script with specified inputs, and tests that its outputs match the outputs set down by the test specification. Examples set specification may be found in the "Shell" and "CLI" projects in the respective "src/test" tree; look for files named "*-tests.xml".
Syntax for test specifications
Let's start with a simple example. This test runs "ExprCommand" command class with the arguments "1 + 1", and checks that it writes "2" to standard output and sets the return code to "0".
<testSpec title="expr 1 + 1" command="org.jnode.shell.command.posix.ExprCommand"
runMode="AS_ALIAS" rc="0">
<arg>1</arg>
<arg>+</arg>
<arg>1</arg>
<output>2
</output>
</testSpec>
Notes:
- The odd indentation of the closing "output" tag is is not a typo. This element is specifying that the output should consists of a "2" followed by a newline. If the closing tag was indented, the test would "expect" a couple of extra space characters after the newline, and this would cause a spurious test failure.
- Any literal '<', '>' and '&' characters in the XML file must be suitably "escaped"; e.g. using XML character entities;
An "testSpec" element and its nested elements specifies a single test. The elements and attributes are as follows:
- "title" (mandatory attribute)
- gives a title for the test to identify it in test reports.
- "command" (mandatory attribute)
- gives the command name or class name to be used for the command / script.
- "runMode" (optional attribute)
- says whether the test involves running a command alias or class ("AS_ALIAS") in the same way as the JNode CommandShell would do, running a script ("AS_SCRIPT"), or executing a class via its 'main' entry point ("AS_CLASS"). The default for "runMode" is "AS_ALIAS".
- "rc" (optional attribute)
- gives the expected return code for the command. The default value is "0". Note that the return code cannot be checked when the "runMode" is "AS_CLASS".
- "trapException" (optional attribute)
- if present, this is the fully qualified classname of an exception. If the test throws this exception or a subtype, the exception will be trapped, and the harness will proceed to check the test's post-conditions.".
- "arg" (optional repeated elements)
- these elements gives the "command line" arguments for the command. If they are omitted, no arguments are passed.
- "script" (conditional element)
- if "runMode" is "AS_SCRIPT", this element should contain the text of the script to be executed. The first line should probably be "#!<interpreter-name>".
- "input" (optional element)
- this gives the character sequence that will be available as the input stream for the command. If this element is absent, the command will be given an empty input stream.
- "output" (optional element)
- this gives the expected standard output contents for the command. If this element is absent, nothing is expected to be written to standard output.
- "error" (optional element)
- this gives the expected standard error contents for the command. If this element is absent, nothing is expected to be written to standard error.
- "file" (optional repeating element)
- this gives an input or output file for the test, as described below.
Syntax for "file" elements
A "file" element specifies an input or output file for a test. The attributes and content
are as follows:
- "name" (mandatory attribute)
- gives the file name. This must be relative, and will be resolved relative to the test's temporary directory.
- "input" (optional attribute)
- if "true", the element's contents will be written to a file, then made available for the test or harness to read, If "false", the element's contents will be checked against the contents of the file after the test has run.
- "directory" (optional attribute)
- if "true", the file denotes a directory to be created or checked. In this case, the "file" element should have no content.
Script expansion
Before a script is executed, it is written to a temporary directory. Any @TEMP_DIR@ sequence in the script will be replaced with the name of the directory where input files are created and where output files are expected to appear.
Syntax for test sets
While the test harness can handle XML files containing a single <testSpec> element, it is more convenient to assemble multiple tests into a test set. Here is a simple example:
<testSet title="expr tests""> <include setName="../somewhere/more-tests.xml"/> <testSpec title="expr 1 + 1" ...> ... </testSpec> <testSpec title="expr 2 * 2" ...> ... </testSpec> </testSet>
The "include" element declares that the tests in another test set should be run as part of this one. If the "setName" is relative, it will be resolved relative to this testSet's parent directory. The "testSpec" elements specify tests that are part of this test set.
Plugin handling
As a general rule, JNode command classes amd aliases are defined in plugins. When the test harness is run, it needs to know which plugins need to be loaded or the equivalent if we are running on the development platform. This is done using "plugin" elements; for example:
...
<plugin id="org.jnode.shell.bjorne"
class="org.jnode.test.shell.bjorne.BjornePseudoPlugin"/>
<plugin id="org.jnode.shell.command.posix"/>
...
These elements may be child elements of both "testSpec" or "testSet" elements. A given plugin may be specified in more than one place, though if a plugin is specified differently in different places, the results are undefined. If a "plugin" element is in a "testSpec", the plugin will be loaded before the test is run. If a "plugin" element is in a "testSet", the plugin will be loaded before any test in the set, as well as any test that are "included".
The "plugin" element has the following attributes:
- "id" (mandatory attribute)
- gives the identifier of the plugin to be loaded.
- "version" optional attribute)
- gives the version string for the plugin to be loaded. This defaults to JNode's default plugin version string.
- "class" optional attribute)
- gives the fully qualified class name for a "pseudo-plugin" class; see below.
When the test harness is run on JNode, a "plugin" element causes the relevant Plugin to be loaded via the JNode plugin manager, using the supplied plugin id and the supplied (or default) version string.
When the test harness is run outside of JNode, the Emu is used to provide a minimal set of services. Currently, this does not include a plugin manager, so JNode plugins cannot be loaded in the normal way. Instead, a "plugin" element triggers the following:
- The plugin descriptor file is located and read to extract any aliases and command syntaxes. This information is added to Emu's alias and syntax managers.
- If the "plugin" element includes a "class" attribute, the corresponding class is loaded and the default constructor is called. This provides a "hook" for doing some initialization that would normally be done by the real Plugin. For example, the "plugin" in the bjorne tests use the "BjornePseudoPlugin" class to registers the interpreter with the shell services. (This is normally done by "BjornePlugin".)
Virtual Machine
This part contains the technical documentation of the JNode virtual machine.
Arrays
Arrays are allocated just like normal java objects. The number of elements of the array is stored as the first (int) instance variable of the object. The actual data is located just after this length field.
Bytecodes that work on arrays are do the index checking. E.g. on the X86 this is implemented using the bound instruction.
Classes & Objects
Each class is represented by an internal structure of class information, method information and field information. All this information is stored in normal java objects.
Every object is located somewhere in the heap. It consists of an object header and space for instance variables.
Exceptions
At the start of each method invocation a frame for that method is created on the stack. This frame contains references to the calling frame and contains a magic number that is used to differentiate between compiled code invocations and interpreted invocations.
When an exception is thrown, the exception table of the current method is inspected. When an exception handler is found, the calculation stack is cleaned and code executing continues at the handler address.
When no suitable exception handler is found in the current method, the stackframe of the current method is destroyed and the process continues at the calling method.
When stacktrace of an exception is created from the frames of each method invocation. A class called VmStackFrame has exactly the same layout as a frame on the stack and is used to enumerate all method-invcocations.
Garbage collection
JNode uses a simple mark&sweep collector. You can read on the differences, used terms and some general implementation details at wikipedia. In these terms JNode uses a non-moving stop-the-world conservative garbage collector.
About the JNode memory manager you should know the following: There is org.jnode.vm.memmgr.def.VmBootHeap. This class manages all objects that got allocated during the bootimage creation. VmDefaultHeap contains objects allocated during runtime. Each Object on the heap has a header that contains some extra information about the heap. There's information about the object's type, a reference to a monitor (if present) and the object's color (see wikipedia). JNode objects can have one of 4 different colors and one extra finalization bit. The values are defined in org.jnode.vm.classmgr.ObjectFlags.
At the beginning of a gc cycle all objects are either WHITE (i.e. not visited/newly allocated) or YELLOW (this object is awaiting finalization).
The main entry point for the gc is org.jnode.vm.memmgr.def.GCManager#gc() which triggers the gc run. As you can see one of the first things in gc() is a call to "helper.stopThreadsAtSafePoint();" which stops all threads except the garbace collector. The collection then is divided into 3 phases: markHeap, sweep and cleanup. The two optional verify calls at the beginning and end are used for debugging, to watch if the heap is consistent.
The mark phase now has to mark all reachable objects. For that JNode uses org.jnode.vm.memmgr.def.GCStack (the so called mark stack) using a breadth-first search (BFS) on the reference graph. At the beginning all roots get marked where roots are all references in static variables or any reference on any Thread's stack. Using the visitor pattern the Method org.jnode.vm.memmgr.def.GCMarkVisitor#visit get called for each object. If the object is BLACK (object was visited before and all its children got visited. Mind: This does not mean that the children's children got visited!) we simply return and continue with the next reference in the 'root set'. If the object is GREY (object got visited before, but not all children) or in the 'root set' the object gets pushed on the mark stack and mark() gets called.
Let's make another step down and examine the mark() method. It first pops an Object of the mark stack and trys to get the object type. For all children (either references in Object arrays or fields of Objects) the processChild gets called and each WHITE (not visited yet) object gets modified to be GREY. After that the object gets pushed on the mark stack. It is important to understand at that point that the mark stack might overflow! If that happens the mark stack simply discards the object to push and remembers the overflow. Back at the mark method we know one thing for sure: All children of the current object are marked GREY (or even BLACK from a previous mark()) and this is even true if the mark stack had an overflow. After examining the object's Monitor and TIB it can be turned BLACK.
Back at GCManager#markHeap() we're either finished with marking the object or the mark stack had an overflow. In the case it had an overflow we have to repeat the mark phase. Since many objects now are allready BLACK it is less likly the stack will overflow again but there's one important point to consider: All roots got marked BLACK but as said above not all children's children need to be BLACK and might be GREY or even WHITE. That's why we have to walk all heaps too in the second iteration.
At the end of the mark phase all objects are either BLACK (reachable) or WHITE (not reachable) so the WHITE ones can be removed.
The sweep again walks the heap (this time without the 'root set' as they do not contain garbage by definition) and again visits each object via org.jnode.vm.memmgr.def.GCSweepVisitor#visit. As WHITE objects are not reachable anymore it first tests if the object got previously finalized. If it was it will be freed, if not and the object has a Finalizer it will be marked YELLOW (Awaiting finalization) else it will be freed too. If the object is neither WHITE nor YELLOW it will be marked WHITE for the next gc cycle.
The cleanup phase at the end sets all objects in the bootHeap to WHITE (as they will not be swept above) as they might be BLACK and afterwards calls defragment() for every heap.
Some other thoughts regarding the JNode implementation include:
It should be also noted that JNode does not know about the stack's details. I.e. if the mark phase visits all objects of a Thread's stack it never knows for a value if it is a reference or a simple int,float,.. value. This is why the JNode garbage collector can be called conservative. Every value on the stack might be a reference pointing to a valid object. So even if it is a float on the stack, as we don't know for sure we have to visit the object and run a mark() cycle. This means on the one hand that we might mark memory as reachable that in reality is garbage on the other hand it means that we might point to YELLOW objects from the stack. As YELLOW objects are awaiting finalization (and except the case the finalizer will reactivate the object) they are garbage and so they can not be in the 'root set' (except the case where we have a random value on the stack that we incorrectly consider to be a reference). This is also the reason for the current "workaround" in GCMarkVisitor#visit() where YELLOW objects in the 'root set' trigger error messages instead of killing JNode.
There is some primilary code for WriteBarrier support in JNode. This is a start to make the gc concurrent. If the WriteBarrier is enabled during build time, the JNode JIT will include some special code into the compiled native code. For each bytecode that sets a reference to any field or local the writebarrier gets called and the object gets marked GREY. So the gc will know that the heap changed during mark. It is very tricky to do all that with proper synchronization and the current code still has bugs, which is the reason why it's not activated yet.
Java Security
This chapter covers the Java security implemented in JNode. This involves the security manager, access controller and privileged actions.
It does not involve user management.
The Java security in JNode is an implementation of the standard Java security API. This means that permissions are checked against an AccessControlContext which contains ProtectionDomain's. See the Security Architecture for more information.
In JNode the security manager is always on. This ensures that permissions are always checked.
The security manager (or better the AccessController) executes the security policy implemented by JNodePolicy. This policy is an implementation of the standard java.security.Policy class.
This policy contains some static permissions (mainly for access to certain system properties) and handles dynamic (plugin) permissions.
The dynamic permissions are plugin based. Every plugin may request certain permissions. The Policy implementation decides if these permissions are granted to the plugin.
To request permissions for a plugin, add an extension to the plugin-descriptor on connected to the "org.jnode.security.permission" extension-point.
This extension has the following structure:
...
| class | The full classname of the permission. e.g. "java.util.PropertyPermission" |
| name | The name of the permission. This attribute is permission class dependent. e.g. "os.name" |
| actions | The actions of the permission. This attribute is permission class dependent. e.g. "read" |
Multiple permission's can be added to a single extension.
If you need specific permissions, make sure to run that code in a PrivilegedAction. Besides you're own actions, the following standard PrivilegedAction's are available:
| gnu.java.security.actions.GetPropertyAction | Wraps System.getProperty |
| gnu.java.security.actions.GetIntegerAction | Wraps Integer.getInteger |
| gnu.java.security.actions.GetBooleanAction | Wraps Boolean.getBoolean |
| gnu.java.security.actions.GetPolicyAction | Wraps Policy.getPolicy |
| gnu.java.security.actions.InvokeAction | Wraps Method.invoke |
Multi-threading
Multithreading in JNode involves the scheduling of multiple java.lang.Thread instances between 1 or more physical processors. (In reality, multiprocessor support is not yet stable). The current implementation uses the yieldpoint scheduling model as described below.
Yieldpoint scheduling
Yieldpoint scheduling means that every thread checks at certain points (called "yieldpoints") in the native code to see if it should let other threads run. The native code compiler adds yieldpoints into the native code stream at the beginning and end of a method, at backward jumps, and at method invocations. The yieldpoint code checks to see if the "yield" flag has been set for the current thread, and if is has, it issues a yield (software-)interrupt. The kernel takes over and schedules a new thread.
The "yield" flag can be set by a timer interrupt, or by the (kernel) software itself, e.g. to perform an explicit yield or in case of locking synchronization methods.
The scheduler invoked by the (native code) kernel is implemented in the VmProcessor class. This class (one instance for every processor) contains a list of threads ready to run, a list of sleeping threads and a current thread. On a reschedule, the current thread is appended to the end of the ready to run thread-list. Then the sleep list is inspected first for threads that should wake-up. These threads are added to the ready to run thread-list. After that the first thread in the ready to run thread-list is removed and used as current thread. The reschedule method returns and the (native code) kernel does the actual thread switching.
The scheduler itself runs in the context of the kernel and should not be interrupted. A special flag is set to prevent yieldpoints in the scheduler methods themselves from triggering reentrant yieldpoint interrupts. The flag is only cleared when the reschedule is complete
Why use yieldpoint scheduling?
JNode uses yield point scheduling to simplify the implementation of the garbage collector and to reduce the space needed to hold GC descriptors.
When the JNode garbage collector runs, it needs to find all "live" object references so that it can work out which objects are not garbage. A bit later, it needs to update any references for objects that have been moved in memory. Most object references live either in other objects in the heap, or in local variables and parameters held on one of the thread stacks. However, when a thread is interrupted, the contents of the hardware registers are saved in a "register save" area, an this may include object references.
The garbage collector is able to find these reference because the native compiler creates descriptors giving the offsets of references. For each class, there is a descriptor giving the offsets of its reference attributes and statics in their respective frames. For each method or constructor, another descriptor gives the corresponding stack frame layout. But we still have to deal with the saved registers.
If we allowed a JNode thread to be interrupted at any point, the native compiler would need to create descriptors all possible saved register sets. In theory, we might need a different descriptor corresponding to every bytecode. By using yield points, we can guarantee that "yields" only occur at a fixed places, thereby reducing the number of descriptors that that need to be kept.
However, the obvious downside of yieldpoints is the performance penalty of repeatedly testing the "yield" flag, especially when executing a tight loop.
Thread priorities
Thread can have different priorities, ranging from Thread.LOW_PRIORITY to Thread.HIGH_PRIORITY. In JNode these priorities are implemented via the ready to run thread-list. This list is (almost) always sorted on priority, which means that the threads with the highest priority comes first.
There is one exception on this rule, which is in the case of busy-waiting in the synchronization system. Claiming access to a monitor (internals) involves a busy-waiting loop with an explicit yield. This yield ignores the thread priority to avoid starvation of lower-priority threads, which will lead to an endless waiting time for the high priority thread.
Classes involved
The following classes are involved in the scheduling system. All of these classes are in the org.jnode.vm package.
- VmProcessor
- VmThread contains the internal (JNode specific) data for a single thread. This class is extended for each specific platform
Native code compilation
All methods are compiled before being executed. At first, the method is "compiled" to a stub that calls the most basic compiler and then invokes the compiled code.
Better compilers are invoked when the VM detects that a method is invoked often. These compilers perform more optimizations.
Intel X86 compilers
JNode has now two different native code compilers for the Intel X86 platform and 1 stub compiler.
STUB is a stub compiler that generates a stub for each method that invokes the L1 compiler for a method and then invokes the generated code itself. This compiler ensures that method are compiled before being executed, but avoids compilation time when the method is not invoked at all.
L1A is a basic compiler that translated java bytecode directly to decent X86 instructions. This compiler uses register allocation and a virtual stack to eliminate much of the stack operations. The focus of this compiler is on fast compilation and reasonably fast generated code.
L2 is an optimizing compiler that focuses on generating very fast code, not on compilation speed. This compiler is currently under construction.
All X86 compilers can be found below the org.jnode.vm.x86.compiler package.
IR representation
Optimizing compilers use an intermediate representation instead of java bytecodes. The intermediate representation (IR) is an abstract representation of machine operations which are eventually mapped to machine instructions for a particular processor. Many optimizations can be performed without concern for machine details, so the IR is a good start. Additional machine dependent optimizations can be performed at a later stage. In general, the most important optimizations are machine independent, whereas machine dependent optimizations will typically yield lesser gains in performance.
The IR is typically represented as set of multiple operand operations, usually called triples or quads in the literature. The L2 compiler defines an abstract class org.jnode.vm.compiler.ir.quad.Quad to describe an abstract operation. Many concrete implementations are defined, such as BinaryQuad, which represents binary operations, such as a = x + y. Note that the left hand side (lhs) of the operation is also part of the quad.
A set of Quads representing bytecodes for a given method are preprared by org.jnode.vm.compiler.ir.IRGenerator.
L2 Compiler Phases
The L2 compiler operates in four phases:
1. Generate intermediate representation (IR)
2. Perform second pass optimizations (pass2)
3. Register allocation
4. Generate native code
The first phase parses bytecodes and generates a set of Quads. This phase also performs simple optimizations, such as copy propagation and constant folding.
Pass2 simplifies operands and tries to eliminate dead code.
Register allocation is an attempt to assign live variable ranges to available machine registers. As register access is significantly faster than memory access, register allocation is an important optimization technique. In general, it is not always possible to assign all live variable ranges to machine registers. Variables that cannot be allocated to registers are said to be 'spilled' and must reside in memory.
Code is generated by iterating over the set of IR quads and producing machine instructions.
Object allocation
All new statements used to allocate new objects are forwarded to a HeapManager. This class allocates & initializes the object. The objects are allocated from one of several heaps. Each heap contains objects of various sizes. Allocation is currently as simple as finding the next free space that is large enough to fit all instance variables of the new object and claiming it.
An object is blanked on allocation, so all instance variables are initialized to their default (null) values. Finally the object header is initialized, and the object is returned.
To directly manipulate memory at a given address, a class called Unsafe is used. This class contains native methods to get/set the various java types.
Synchronization
Synchronization involves the implementation of synchronized methods and blocks and the wait, notify, notifyAll method of java.lang.Object.
Both items are implemented using the classes Monitor and MonitorManager.
Lightweight locks
JNode implement a lightweight locking mechanism for synchronized methods and blocks. For this purpose a lockword is added to the header of each object. Depending on the state of the object on which a thread wants to synchronize a different route it taken.
This is in principle how the various states are handled.
- The object is not locked: the lockword it set to a merge of the id of this thread and a lockcount of '1'.
- The object is locked by this thread: the lockcount part of the lockword is incremented.
- The object is locked by another thread: an inflated lock is installed for the object and this thread is added to the waiting list of the inflated lock.
All manipulation of the lockword is performed using atomic instructions prefixed with multiprocessor LOCK flags.
When the lockcount part of the lockword is full, an inflated lock is also installed.
Once an object has an inflated lock installed, this inflated lock will always be used.
Wait, notify
Wait and notify(all) requires that the current thread is owner of the object on which wait/notify are invoked. The wait/notify implementation will install an inflated lock on the object if the object does not already have an inflated lock installed.
Reports
The following reports are generated nightly reflecting the state of SVN trunk.
Plugins:
Javadocs:
Nightly build:
Tester guide
This part is intended for JNode testers.
Filesystem
Here you can find informations related to the tests on filesystems.
Running the tests outside of JNode
With Ant run the target tests in the file /JNode-All/build.xml.
The results are sent to the standard output and unexpected exceptions are also sent as for any other JAVA application.
To debug the functionalities whose tests are failing, you can use Log4j that is configured through the file /JNode-FS/src/test/org/jnode/test/log4jForTests.properties.
By default traces are sent to the localhost on the port 4445. I recommand to use Lumbermill as a server to receive the log4j messages.
Running the tests in JNode
Type AllFSTest in the JNode shell. The results and unexpected exceptions are sent to the console. Log4j is automatically configured by JNode itself and manually with the shell command log4j.
Network
We assume in the following tests that IP address of JNode is 192.168.44.3.
- configure the network in JNode
- Testing the telnet server
- In JNode shell : type telnetd. The telnet server will start on port 6666
- In another OS (Linux, Windows...) : connect to the telnet server by typing telnet 192.168.44.3 6666.
Running black-box tests
The JNode-shell project includes a test harness for running "black-box" tests on JNode commands and scripts. The harness is designed to allow tests to be run both in a development sandbox and on a running JNode system.
The test methodology is very straight-forward. Each testcase consists of a JNode alias, Java classname or inline script, together with an optional set of arguments and an optional inline input file. The command (alias or class) or script it run with the prescribed arguments and input, and the resulting output stream, error stream and return code are compared with expected results in the testcase. If there are any discrepancies between the expected and actual results, the testcase is counted as "failed". If there are any uncaught exceptions, this counts as a test "error".
The testcases are specified in XML files. Examples may be found in the JNode-Shell project in the "src/test" tree; e.g. "src/test/org/jnode/test/shell/bjorne/bjorne-shell-tests.xml". Each file typically specifies a number of distinct testcases, as outlined above. The "all-tests.xml" file (i.e. "shell/src/test/org/jnode/test/shell/all-tests.xml") should include all tests in the shell tree.
Running tests from Eclipse
The following steps can be used to run a set of tests from Eclipse.
- Launch Eclipse, switch to your JNode workspace, and open the JNode-shell project.
- Navigate to the class "org.jnode.test.shell.harness.TestHarness" ... it is in the "src/test" tree.
- Use "Run as>Open Run dialog" to create an app launcher for the TestHarness class.
- Set the full classname as above and set the Arguments to the name of a "...-tests.xml" file.
- If you are testing commands in a different project from "shell", make sure that the project is on the launcher's classpath.
- Use the launcher to run the TestHarness.
You should now see a Console view displaying the output from running the tests. The last line should give a count of tests run, failures and errors.
Running tests from the Linux shell
Running the tests from the Linux shell is simply a matter of doing what the Eclipse launcher is doing. Put the relevant "JNode-*/classes" directories on the classpath, then run:
java org.jnode.test.shell.harness.TestHarness <xxx-tests.xml>
Running tests from within JNode.
In order to run the tests on the JNode platform, you must first boot JNode with the all plugins and tests loaded. Then, run the following command at the JNode command prompt:
org.jnode.test.shell.harness.TestHarness -r /org/jnode/test/shell/all-tests.xml
Notes:
- The "-r" option tells the test harness to locate the test suite specification as a resource using the classloader. So you need to make sure that the specification and dependent specifications are included in the relevant test plugins.
- When using "-r", the resource path should be specified using "/" as the path separator, not ".". The resource path will be treated as absolute whether or not it starts with a "/".
- An alternative to "-r" might be to arrange that the test suite / test specification are accessible through JNode's file system; e.g. by uploading them to JNode before running the test harness.
TestHarness command syntax.
The TestHarness command has the following syntax:
command [ <opt> ...] <spec-file> ...
where <opt> is one of:
--verbose | - v # output more information about tests run
--debug | - d # enable extra debugging
--stopOnError | -E # stop test harness on the first 'error'
--stopOnFailure | -F # stop test harness on the first 'failure'
--sandbox | -s <dir-name> # specifies the dev't sandbox root directory
--resource | -r # looks for <spec-file> as a resource on the classpath
The first two options enable more output. In particular, "-d" causes all output captured by the harness to be echoed to the console as it is captured.
The "-s" option can be used when the running the test harness outside of JNode when the root of the development sandbox is not "..".
The "-r" option tells the harness to try to find the test specification files on TestHarness's classpath rather in the file system. This allows the test harness to be run on JNode without the hassle of copying test and test suite specification files into the JNode filesystem.
Note that the TestHarness command class does not implement JNode's "Command" API, so command completion is not available when running on JNode. This is a deliberate design decision, not an oversight.
Reading and writing test specifications.
If a test fails, you will probably need to read and understand the test's specification as a first step in diagnosing the problem. For a description of specification file syntax and what they mean, please refer to the Black-box command tests with TestHarness page.
Running Mauve Tests
To run the mauve tests, proceed as follow :
- boot JNode and choose the choose the option "all plugins + tests" (should be the latest choice in the menu), that will allow you to use the mauve plugin.
- when boot is finished, type the command cd /jnode/tmp to go in a writable directory
- type mauve-filter and answer to the asked questions, that will create a file named "tests" in the current directory
- type testCommand and the tests will run
If you find some bugs by this way, don't forget to submit it or fix it. Depending on the case, it is possible that a patch to fix the bug is needed on Classpath/Openjdk side ... and/or on JNode side.
Running sandbox tests
We have created a straight-forward way to run various tests from the Linux commandline in the development sandbox. The procedure is as follows:
- Change directory to the sandbox root.
- Run the "test.sh" script as follows:
$ ./test.sh all
For brief help on the script's arguments, just run "./build.sh" with no arguments.
The "./build.sh" script is just a wrapper script for using Ant to run tests that are
defined as targets in the "<project>/build-tests.xml" files. You can add new
tests to be run by adding targets, or (if required) cloning an existing file into
a project that doesn't have one.
Running the test server (JTestServer)
TODO
Porting guide
This guide is intended for developers porting JNode to different platforms.
Porting JNode to another platform involves the components:
- The nano-kernel (assembler)
- The native methods (assembler)
- The architecture specific classes
- The native code compilers
- The build process
Nano-kernel
The nano-kernel is the piece of code that is executed when JNode boots. It is responsible for setting the CPU into the correct mode and initialize the physical memory management structures (like page tables, segments etc).
The nano-kernel is also responsible for caching and dispatching hardware interrupts.
Native methods
The Unsafe class contains some native methods that must be implemented according to the given architecture.
Architecture specific classes
The JNode system requires some specific classes for each architecture. These classes describe the architecture like the size of an object reference and implement architecture specific items like thread states and processor information.
The essential classes needed for every architecture are:
- A class derived from VmArchitecture
- A class derived from VmProcessor
- A class derived from VmThread
Native code compilers
At least 1 native code compiler must be written for an architecture. This compiler generates native code for java methods.
It is possible to implement multiple native code compilers for a specific architecture. Every compiler has a specific optimization level.
Part of the native code compiler infrastructure is usually an assembler. This assembler is a java class that writes/encodes native code instructions. The assembler is used by the native code compilers and usually the build process.
Build process
A final but important part of a port to a specific architecture is the build process. The standard JNode build files will compile all java code, prepare plugins and initial jar files, but will not build any architecture dependent structures.
The build process contains an architecture specific ant-file which will call a task used to create the JNode kernel. This task is derived from AbstractBootImageBuilder.
Project development
This part contains all release plans, the projects organization and the development process in general.
Project organization
Development teams
Development in the JNode project is done in development teams.
These teams have been introduced to:
- Focus development efforts
- Shorten learning curve for new developers
- Delegate project control
Overall coordination of the JNode project remains in the hands of the
projects founder: Ewout Prangsma.
JNode-Core
This team will develop the virtual machine itself and the basic structure of the JNode kernel.
Team members
- Ewout Prangsma, teamleader
- Madhu Siddalingaiah
- Patrik Reali
Topics:
The plugin framework, The device framework, The VM, classloaders, native code compilers, memory management, The build & boot process, PCI drivers.
All development issues are discusses in our forum.
Targets for the near future:
- Finalize integrate optimizing native code compiler
- Load/unload/reload plugins at runtime
- Load/unload/reload drivers at runtime
- Start security system
- Plugin install, upgrade & uninstall framework
Targets for the longer term:
- Fully concurrent GC
- Improve memory allocation speed
JNode-FS
This team will develop the filesystem layer of JNode.
Team leader: Guillaume BINET.
Topics:
The filesystem framework, The various filesystems, The integration with java.io, java.nio, Block device drivers (IDE, Floppy, SCSI, Ramdisk)
All development issues are discusses in our forum.
JNode-GUI
This team will develop the graphics layer of JNode.
Team leader: Valentin Chira.
Topics:
The AWT implementation, The window manager, The input handlers (keyboard/mouse) & drivers, Video drivers
All development issues are discusses in our forum.
JNode-Net
This team will develop the network layer of JNode.
Team leader: Martin Husted Hartvig.
Topics:
The networking framework, The various network protocols, The integration with java.net, Network drivers
Team members:
Lesire Fabien
Mark Hale
Pavlos Georgiadis
Christopher Cole
Eduardo Millan
All development issues are discusses in our forum.
JNode-Shell
This team will develop the command line shell and the basic commands.
Team leader: Bengt Baverman.
Topics:
The command line shell, including the help system, The basic commands, Help the development of other parts of JNode to support the Shell
All development issues are discusses in our forum.
How to join the development team
We always welcome new dedicated developers.
Following content is outdated since we have moved to GitHub.
If you want to join the development team, contact one of the developers who is working on an issue you want to contribute to, or contact the project admin for more information.
You will be asked to submit your first patches via email, before you'll be granted access to the SVN repository.
Draft 0.2 plan
The document lays out the feature set for the next major release of JNode designated release 0.2.
This plan is intended to guide the development towards our first major release. It is not a fixed plan that cannot be deviated from. Suggestions & remarks are always welcome and will be considered.
Release target
We want this release to be the first usable version of JNode where we can run real world Java programs on.
This means that we need a working filesystem, a stable virtual machine, a class library mostly compatible with JDK 1.1, a working TCP/IP implementation and way to install it on a PC. It is not expected to have a fully working GUI yet.
Additional features
To achieve the target outlined above, each team will have to add/complement a number of features. These features are listed below. The percentages specify finised work, so 100% means completed.
JNode-Core
- 100% - Dynamically (re)loadable plugins
- 10% - Plugin install, upgrade & uninstall framework
- 50% - Second level native code compiler target as good (native) code quality
- 100% - Security system
- 0% - Setup utility
- 80% - Implementation of java.lang package
- 80% - Implementation of java.math package
- 60% - Implementation of java.security package
- 90% - Implementation of java.util package
- 80% - Implementation of java.util.jar package
- 80% - Implementation of java.util.zip package
JNode-FS
- 80% - Virtual filesystem (in progress)
- 60% - Implementation of java.io package
- 90% - R/w ext2 implementation
- 20% - R/w fdisk services
- ? - Format services for ext2
- 95% - ATAPI driver
- 95% - CDROM (ISO9660) filesystem
JNode-GUI
- 0% - Textmode userinterface for use in installer
JNode-Net
- 25% - TCP/IP stack, client & server
- 75% - Implementation of java.net package
JNode-Shell
- 100% - Commands to modify the classpath
- 100% - Commands to run java code, both .class and .jar files from any location
Release milestones
Right now no date is set for this release. There will be intermediate releases reflecting the state of development on the 0.1.x series until the target is reached.
Looking towards the future; 0.3
The next major release after 0.2 should bring a graphical user interface, we should really consider using J2SDK 1.5 features like generic types and add numerous drivers for CDROMs, USB, Video cards.
Draft 0.3 plan
The document lays out the feature set for the next major release of JNode designated release 0.3.
This plan is intended to guide the development towards our second major release. It is not a fixed plan (as we have seen with the 0.2 release). Suggestions & remarks are always welcome and will be considered.
Release target
This release will improve the stability of the JNode operating system and enhance the usability.
Global enhancements
A major goal of this release is to reduce the memory footprint required by JNode. The VM will be enhanced to support this, and all parts of JNode will have to be more concerned about their memory usage.
JNode will become localizable and translations for some locales will be added.
Every new part of JNode will have to be localizable according to a set of rules that will be determined.
The one and only language for the source code of JNode is and will remain to be English.
The remainder of this page will describe the targets and enhancements of the various subprojects of JNode. The names between brackets in the enhancements sections are the names of the lead developer for that enhancement.
The enhancements are given a priority:
- Highest priority
- Second priority
- Lowest priority
Core: Virtual Machine & Operating system
The virtual machine will become more stable, reduce memory usage and will add support for Isolates (JSR 121). Furthermore it will enhance the J2SDK compatibility level.
The operating system will add support for power management and make enhancements for that in the driver framework.
An installer will be developed that is used to install JNode onto a PC system. This installer will put the essential structures/files on the harddisk of the PC.
A persistent storage mechanism for plugin preferences will be added.
Enhancements:
 Isolate support [ewout]
Isolate support [ewout]- Annotation support [ewout]
- Multi CPU support [ewout]
- Integrate MMTK garbage collector [ewout]
- Smart field alignment, to reduce the size of objects [ewout]
- Overall memory reduction [ewout]
- Power management support [ewout]
- API for halt, sleep & reboot of JNode [ewout]
- Installer [martin]
- Persistent storage for plugin preferences
- Access to detailed information about system information such as classes & their usage
- Fragmented plugin support [ewout]
Networking
The network layer will be enhanced to fully support wireless networks. Furthermore, the existing TCP/IP stack will be improved in terms of reliability, safety and speed.
Enhancements:
- Wireless network support [martin]
- Wireless netcard drivers [martin]
- TCP server side fixes [galatnm]
- EEPRO100 driver [galatnm]
File system
The filesystem layer will become more stable and will be refactored to make use to the NIO classes.
Support will be added for a virtual filesystem that allows links between filesystems.
A new "system" filesystem will be added that gives access to a distributed filesystem that contains the JNode system information. This system information is about plugins, kernels & preferences.
Enhancements:
- Change file system api's to use ByteBuffers [fabien]
- Update java.io to latest classpath version based on NIO classes [fabien]
- System filesystem [ewout]
- USB storage driver [galatnm]
- Extend support for EXT2 to EXT3
- Add write & format support to NTFS
- Generic block cache for block devices [fabien]
GUI
The existing GUI will be improved in terms of stability, Java2D support and speed.
The video driver interface may be adjusted to make better use of hardware acceleration.
A user friendly desktop environment will be developed or integrated.
Enhancements:
- Enhance java2D support
- Improve use of hardware acceleration
- Improve font rendering
- Improve Swing awt peers [levente]
- User friendly desktop environment [levente]
Shell
The shell will be extended with a graphical console, in order to display not ASCII characters.
Enhancements:
- Graphical console
- Add Isolate command invoker
Developer support
We want to make life of the JNode developer much easier. This will mean adding good documentation and also provide ways to develop JNode in JNode.
Enhancements:
TODO list
The document states some of the TODOs with regard to future releases of JNode. There is no particular date when the targets should be finished, but it should give you some hints, what you could look at :
- XYZ Filesystem: There are many other filesystems that could be added to JNode. Or existing readonly filesystems could be extended for write support. A list of possibilities includes: NFS, Samba, ssh fs, ftp write support, ntfs write support, ...
- Partitiontool: We need harddisk partitioning support. That includes a commandline version like fdisk but could also be extended for a graphical version. The GUI version can be written using charva or swing or both
- Grubinstaller: Some code to be able to install grub to the harddisk. That means, install stage1 into MBR, stage1.5 as needed and for both files the hidden data structures have to be updated. A "highlevel editor" for the menu.lst file would be fine, too.
- HTMLDemo: Classpath contains a little "webbrowser", it would be nice as a showcase for JNode. It's contained in examples.zip, but it has to be extended, because at the moment it's only usable for testing classpaths HTML renderer
- Device Drivers: Device Drivers are a very important part of an operating system. If you have a peace of hardware that isn't included in JNode yet, and you have some hardware/lowlevel skills you're welcome to add support for it. This includes either adding support for a new hardware for an existing API (e.g. network cards, graphic cards, HIDs,...) but also adding hardware that was not present in JNode before (e.g. Framegrabber (bttv,..), CD Writer,...).
- SWTswing: Port of SWTswing to JNode. This is needed to be able to run eclipse inside JNode. BTW, if that works, porting eclipse is the next TODO on the list
- JSR80: Interfacing the current JNode usb api to the javax.usb api as descriped in JSR80 API Specification.
- JNodeTools: Implement a tool to create and edit the plugin descriptors. Either as a eclipse tool or standalone app (so it can be used in JNode too). See also here
- JNode Commands: We need to expand and improve the suite of JNode utility commands that can be run from the command line. Rather than reinventing the wheel, JNode commands should aim to be compatible with commands defined in the relevant POSIX specification; i.e. IEEE Std 1003.1, 2004 Edition
Student Projects
In order to imply students in JNode, I will expose here some projects.
Git repository
The gitorious project is located here : http://gitorious.org/jnode.
It's compound of:
- svn-mirror, which is a mirror of the subversion repository
- a set a clones of svn-mirror, one for each student project
Contact
If you are interested, you can contact me (Fabien DUMINY) :
- with my jnode.org contact form (in english or french)
- with my blog contact form :
Remarks
- Since it's a draft, that document may evolve
- In order to have some warranty of real work, I have contacted some schools to imply students in these tasks. These students will be served first and in the order of their arrival
Classical projects
Here is a list of classical projects.
Legend :
(A) : project assigned
Level :
(*) : easy
(**) : average
(***) : difficult
(****) : very hard
: unknow
Complete AMD 64 support
- Description : The 64bit port has some bugs but it's not exactly known where and how many. This task is especially difficult as the bugs have to be spotted first. Is this enough work for a student project ?
- Level : Timeconsuming (Depends on finding the bugs)
- Assigned to :
Complete multi CPU support
- Description: Multi-CPU support is broken. There are bugs in JNode's Apic implementation and the scheduler is suboptimal in regard to SMP. This project involves fixing the (L)Apic handling and if time permits replacing the scheduler with an SMP efficient one.
- Level : average/hard (many informations are needed to complete the task)
- Assigned to :
Complete the vesa driver
- Description : The current vesa driver need grub support to detect and set the video mode at boot time. The driver should be extended to become independant of grub (and be able to switch to any supported graphic mode).
- Level : hard (many informations are needed to complete the task)
- References : implements the vbe3 specifications and other references gathered on jnode site
- Assigned to :
Implement full ddx support without 2d and 3d
- Description : With ddx, which stands for full modesetting, you can detect the monitor, you can set any resolution, (sometimes you can rotate the screen) and you have multihead support. From the performance point of view, it will faster than a vesa driver but slower than a chipset specific driver
- Level : moderate/hard
- Assigned to :
Implement javax.comm API (A)
- Description : The javax.comm API allows to access serial and parallel ports in java. I have been told that the javax.comm package can't be used to avoid legal issues : the rxtx project has choosen the gnu.io package instead.
- References : specifications of the API, its javadoc
- Tips : use the RXTX library
- Level : easy
- Assigned to : Mihail Argranat (blog)
Implement new GC algorithms for better performances (A)
- Advice : contact Peter since he has ideas about the subject and could give good practices to avoid breaking jnode for such a task
- You should have read this and understood at least the Basic Algorithm. In the terms of that page, JNode's gc is a conservative, non-moving, non-generational, stop-the-world mark&sweep algorithm. Improvements can be many-fold, basicaly removing one of the "non"s Good information with much stuff about memory management and garbage collection can also be found on this site. You can find another explanation of the naive mark&sweep, with a graph on this site
- Level : This can be anything from easy to extremly hard. Depends on actual task.
- Assigned to : Loïc Rouchon, Benoit Sautel and Ismael Merzaq
Implement realtime specification for Java
Implement virtio drivers for jnode (A) (*/**)
- Description : Virtio allows to have drivers (network, hard drive ...) faster than regular ones running in virtualized environments (kvm, VirtualBox, vmware, xen ...).
- References :
- Rusty Russell (a linux kernel developer) is writting specifications of virtio. He will really appreciate your feedback (his mail is in the document).
- You can also have a look in the sources of the virtio drivers for the linux kernel. You should also have a look at the includes directory (search for virtio*.h files).
- http://www.linux-kvm.org/page/Virtio
- http://lwn.net/Articles/239238/
- http://portal.acm.org/citation.cfm?id=1400108&dl=GUIDE&coll=GUIDE&CFID=5...
- small doc explaining the basic idea : http://ozlabs.org/~rusty/index.cgi/tech/2007-05-21.html
- also look at existing implementations (in kvm)
- Steps
- write a DeviceToDriverMapper that will detect virtio devices in jnode. Look at the function virtio_pci_probe in the linux kernel.
- write a driver for the virtio devices
- block : Look at virtio_blk.h and virtio_blk.c in the linux kernel
- network : Look at virtio_net.h and virtio_net.c in the linux kernel
- Level : easy/average
- Assigned to : Ibrahim Ghiyati and Yi Xenfung
Implement write support for the iso 9660 file system
- Description : iso 9660 is a norm that defines how data are stored in compact discs (cdrom, dvdrom ...). For now, we have only a limited read support for cdroms.
- Level : Hard ?
- Assigned to :
Integrate JDistro
- Description : It would be great to have that advanced desktop in JNode. I am not sure if there is really a licensing issue or not (JDistro is GPL and JNode is LGPL)
- Level : Hard
- Assigned to :
Port jnode to another CPU
Port jnode to grub 2
- Description : Currently, JNode uses the grub bootloader. Using grub 2 would allow to openup to more plateforms like, for example, non BIOS-based architectures (aka EFI ones).
- Level : average/hard (many informations are needed to complete the task)
- Assigned to :
Write a driver for a sound card
- Tips : implement a driver for intelhda since all sound chips nowadays comply with it.
- Level :
- Assigned to :
Write a driver for Serial ATA (sata)
- Reference : Wikipedia page about Serial ATA (sata)
- Tips : implement compliance with ahci.
- Level :
- Assigned to :
Write a file system checker (**/***)
- Description : Writing a file system checker would not only help ensure that a file system is clean at boot time (like linux distro are doing). It will also allow to help fixing bugs in the current implementations of the file systems. For each of these file systems, a checker could be a student project by itself : ext2, fat32, fat12/16, ntfs (I am not sure about that one since it's hard to get ntfs specifications). The first student to work on a file system checker will have to define an API because we don't have yet one.
- Level : Average (depends on the file system complexity)
- Assigned to :
write a virtual keyboard
- Description : look at that topic for more informations
- Tips : JDistro has virtual keyboard which should be made standalone for reuse in JNode but I am not sure if there is really a licensing issue or not (JDistro is GPL and JNode is LGPL) ...
- Level : easy
- Assigned to :
write an open GL driver
- References : open GL organisation
- Level : extremely hard
- Assigned to :
Write another desktop for JNode
- Description : To be specified with the student.
- Level :
- Assigned to :
Generic projects
Here is a list of generic projects
Legend :
(A) : project assigned
Level :
(*) : easy
(**) : average
(***) : difficult
(****) : very hard
: unknow
Implement an API
- Description : which APIs ?
- Level :
- Assigned to :
Write a command
- Description : It could be a big command or a set of smaller commands. It should be Linux commands.
- Level :
- Assigned to :
Write a plugin for eclipse ?
- Description : for doing what ?
- Level :
- Assigned to :
Write drivers for old legacy devices
- Description : which devices ?
- Level :
- Assigned to :
Experimental projects
Here is a list of experimental projects
Legend :
(A) : project assigned
Level :
(*) : easy
(**) : average
(***) : difficult
(****) : very hard
: unknow
Study and experiment usage of gradle as a replacement of our build system
- Description : For now, we are using ant + a set of custom ant tasks. I think gradle, in addition to keep things from ant, maven and ivy, add interesting possibilities :
- groovy scripting ability : more flexibility than xml based build systems. For example, you can do something before and/or after a given (set of) task(s) : it could be used to transform ant's jar task into a jnode's plugin packager (a jnode plugin is a regular jar file which contain a plugin descriptor file)
- interaction with ivy : look at gradle's faq for ivy
- interaction with maven 2 : look at gradle for maven 2 users and gradle's faq for maven
- interaction with ant : look at gradle's faq for ant
- you can find main features here
- Level :
- Assigned to :
Study and experiment usage of OSGi to manage plugins
- Study and experiment usage of OSGi as a replacement of current jnode's specific plugin framework (inspired by eclipse's one)
- Advice : The developer will have to deal with with Classloaders. It sounds to be a very hard task; It might even happen that's not a suitable replacement for our current plugin framework;
Moreover, the incoming modules for openjdk7 (project jigsaw) might come in the way/interfere with osgi. So, in my opinion, it's an heavily experimental task ! - Tips : Look at one of these implementations of OSGi :
- Assigned to :
Contact
Forums
JNode is discussed in several forums. These forums are now prefered above the Sourceforge mailinglists.
IRC
You can also use the #JNode.org at irc.oftc.net IRC channel.
GIT commits
Follow us on GitHub to track all code changes.
Use #JNode to talk about JNode on twitter.
Or else
For all other questions, suggestion and remarks, please contact the project admins: Ewout Prangsma (aka epr), Levente Santha (aka lsantha).
Release procedure
This document describes what is needed to make and publish a new release of JNode.
Preparation
- Start with a clean copy of the SVN trunk (no extra files, no missing files)
- Update all patches to be included in the release
- If the checked-in copy of "builder/lib/jnode-configure-dist.jar" is older than any of the source code for the tool (in "builder/src/configure"), run the following:
$ cp all/build/descriptors/jnode-configure.jar \ builder/lib/jnode-configure-dist.jar $ svn commit builder/lib/jnode-configure-dist.jar - Set the new version number in the "jnode-ver" property in build.xml
- Execute "build clean"
- Execute "build" and verify the build
- Boot and test the system from the network
- Boot and test the system in VMWare
- Execute "build cd-x86"
- Boot and test the system from the CDROM
- Boot and test the system from the CDROM DHCP target
Uploading
- Execute "ant -f all\build.xml upload"
- Create release in SF File Release system
- Mark release hidden
- Write release notes and changelog
- Attach jnode-{version}.iso.gz to release
- Set attributes to "i386", "gz"
- Attach jnodesources-{version}.tar.gz to release
- Set attributes to "Platform independent", "gz"
- Verify the upload by downloading the uploaded files
- Mark release active
Website adjustments
- Add new changelog book page "from {previous-version} to {version}", copy entries from changelog "from {previous-version} to current SVN version"
- Empty changelog "from {previous-version} to current SVN version"
- Create static page "Release {version}", with Download term and mark or change the "Website" option from "<none>" to "Downloads"
SVN actions
- Copy the entire trunk to a branch "jnode_x_y_z" where x, y, z is the version number
- Set the next development version number (x.y.(z+1)-dev) in the "jnode-ver" property in build.xml and check that in
Glossary
This page gives working definitions for common terms that we use in the JNode documentation. While we will try to be consistent with terminology used in other places, we reserve the right to be inconsistent.
- Java Virtual Machine
- A Java Virtual Machine (JVM) is an execution engine for Java programs. A JVM 'executes' bytecodes using various techniques including bytecode interpretation and compilation to / execution of native code.
- Native Code Compiler
- A native code compiler is a compiler that translates a program to native code; i.e. instructions in the instruction set of a physical machine. In the JNode context, the input to the native compiler consists of Java bytecode files.
- Native Compiler
- Short for "native code compiler".
- Bytecode Compiler
- A bytecode compiler is a compiler that translates to Java bytecode files. The input to a bytecode compiler could be Java source code or (in theory) source code in some other programming language.
- JIT Compiler
- A JIT compiler or "Just-in-time" compiler is a native compiler that compiles code at or after class load time. The JNode native code compilers operate as JIT compilers when they run on JNode, and as ahead-of-time (non-JIT) compilers when they used in the build environment to compile code for the JNode boot image.
- Hotspot (tm)
- Hotspot is the name of a family of Sun Java virtual machines; see this Wikipedia page.
- Hotspot
- A hotspot is method or section of code that is determined (by profiling) to be executed very frequently. A profiler-based JIT compiler will typically focus on compiling hotspot methods to native code.
- Boot Image
- This is the memory image loaded by a bootstrap loader to start an operating system such as JNode.
- Boot Image Builder
- The JNode boot image builder creates the JNode boot image as described on the Build Process page.
- Garbage Collector
- The system component that is responsible for reclaiming memory resources for Java objects that have become unreachable.
- Plugin
- An assembly of related classes that are loaded and unloaded together. JNode's plugin mechanism is described in the Plugin Framework page.
- Plugin descriptor
- An XML file that defines the metadata for a plugin and lists its dependencies and exports. A plugin descriptor may also list security permissions granted to classes in the plugin, command aliases and syntaxes, and various plugin-specific configuration information.
- Driver
- A driver is an operating system component that adapts an abstract service API to a particular technology. In JNode, we have "device drivers" that adapt the Device API to hardware devices, file system drivers that adapt the FileSystem APIs for specific file system types, network drivers, frame-buffer drivers and so on.
- Binary Device Driver
- JNode does not support vendor-supplied binary device drivers as a matter of principle. So don't bother asking!
- Service
- A service is a JNode object that performs some important operating system level function. JNode services are typically located using the InitialNamingService.
- Manager
- A manager is a JNode service that manages a collection of resources. For example, the DeviceManager manages the Device instances that have been configured.
- Console
- A console is an abstraction that combines a keyboard and a character oriented display to provide an analog for an old-style "terminal".
- Console mode
- This describes the system state where the (PC) display is in VGA mode, showing an array of (typically) 24x80 fixed width characters.
- Virtual console
- In console mode, JNode supports a number of virtual consoles that are mapped to the physical keyboard and the display. ALT-Fn is used to switch between virtual consoles.
- Shell
- A shell is a JNode object that provides a keyboard-oriented interface for entering commands to be run.
- Command class
- A command class is a Java class with an entry point method that allows a Java application to be run from a command line or script.
- Command Interpreter
- A command interpreter is an object that a JNode shell uses to split command input (and scripts) into commands, and manage their execution. JNode supports multiple command interpreters with different levels of functionality. Command interpreters variously handle such things as stream redirection, setting and expansion of shell variables, file pattern expansion, compound command handling and shell function execution.
- Command Invoker
- A command invoker is an object that a JNode shell uses to run a command class. There are a number of different invokers that run commands in different ways; e.g. in a new Java Thread, a new Proclet or a new Isolate.
- Isolate
- The Isolate mechanism allows applications to be run in JNode that shields them from unwanted affects of other applications. A command or application that is run an isolate appears to be running in its own JVM. Isolates can be safely suspended, resumed and killed. JNode's implementation of Isolates is not yet complete.
- Proclet
- The Proclet mechanism is a JNode specific alternative to Isolates that tries to provide applications with the illusion that they "own" some key bits of global state; i.e. the System.in,out,err streams, the System Properties object and the System Environment object. Since, the illusion is not perfect, we are likely to de-support proclets when the isolate implementation is completed.
- Alias
- An alias is a short name for a command class that is used run it from the command line. For example, "cat" is an alias for "org.jnode.shell.command.CatCommand". Aliases are typically defined in the plugin descriptor file for the command classes plugin.
- Command Syntax
- JNode native commands typically rely on the Command Syntax subsystem to parse the arguments passed to the command. A command registers an abstract syntax for its arguments, and a concrete syntax is defined as a separate XML fragment / file. Common libraries do the work of parsing the arguments, and also provide context sensitive argument completion and command help.
- Unsafe
- Unsafe is a special JNode class (implemented in assembler) that performs certain low-level tasks such as reading and writing to hardware IO ports, and handling low-level 'debug' output; see "kdb".
- Magic
- Magic classes are special classes recognized by the JNode native compiler. These classes typically circumvent the Java type system in some way.
- MagicPermission
- Only classes that are granted this permission may call methods on Magic classes. Examples of classes that require magic permission include hardware device drivers and the heap managers.
- NanoKernel
- This term is historically used to refer to that tiny part of the JNode core which is implemented in x86 assembler. This code mostly deals with bootstrapping and writing to the serial port. The JNode NanoKernel is not a real "nano-kernel" in the conventional sense of the word.
- kdb
- The "kdb" or Kernel DeBugger is JNode NanoKernel functionality that redirects all output from "Unsafe.debug(...)" calls to the serial port. It is used for debugging via low-level system trace-prints and for capturing output from kernel panics. (It is not really a debugger in the conventional sense.)
- Multiboot
- The Multiboot specification is defacto standard for booting operating systems that is supported by many boot loaders and operating systems. JNode's boot image is multiboot compatible.
Please feel free to add extra terms or offer better definitions as comments.
Proposals
In this part of the documentation, new feature, design & architecture proposals are worked out.
Each proposal should contain at least to following topics:
- The goal; what does this proposal want to achieve
- A functional description of the item(s) proposed
- If possible a first architecture and design idea
- References, like standards, other proposals etc
- Names of the submitter(s) of the proposal
Anyone is invited to comment on the proposals.
A New Garbage Collection Algorithm
A while ago I had a suggestion for garbage collection that relied on the MMU units of modern processors. EPR didn't like this for want of a simple/generic solution. So this is a second attempt.
Deep breath, here goes....
Introduction
There are two goals of a OS Java GC:
- Efficiency ideally less than 10% of execution time spent garbage collecting.
- Interactivity. No good if the system halts for 5 minutes GC and preventing use of the system. This is obviously completely inappropiate for a desktop system.
I hope people agree with me so far. So what is the state of play with current algorithms? They mostly seem to be based on the Generational GC principle. That is only GC the memory allocated since the last GC unless the system is out of memory, in which case collect the generation before that and so on.
The problem with this approach, is it delays the inevitable. Eventually a full system GC is required. This halts the system for a large amount of time. Also a simple write barrier is required on pointer writes. This is so the roots to the lastest generation can be detected.
Having said this, generational GC is a good system that works in most environments, it's efficient and modern VM's use generational GC. In my opinion generational GC would work very well with a OS VM if the pause time for the occasional full memory GC could be mitigated. This is what my proposal concerns.
Overview
So lets interleave a slow running full system GC with normal program operation. The problem is the directed connectivaty graph of the program is constantly changing. By requiring to much co-operation between the mutator (running threads) and the GC slows down the mutator. You might end up with a fine grained GC algorithm with no pause times but the whole system would run slowly.
I see the answer as a compromise. Break the memory into chunks. The GC can halt the entire system while it collects the chunk. The bigger the chunk the bigger the pause time but the more efficient the overall system. The advantage of this approach is the integration of the mutator with the GC is very small. In fact no larger than would be required with a traditional generational GC algorithm.
Trapping intra-block pointer writes
So elaborating on the chunk idea, what is required is that we trap all pointer references between chunks. by doing this we have a set of all possible roots to a chunk. For efficiencies sake lets assume all chunks are the same size and are a power of 2. There are no gaps between the chunks and the first starts at byte n * chunksize. Location 0 is memory is a bad page to trap null pointer exceptions. what we're essentially talking about is memory blocks.
Its possible to trap intra-block pointers with three instructions on every pointer write. A smart compiler can cut down the times even this check is done by using the notion that pointer copying local to an object can never trigger the case. This assumes that objects never cross block boundaries. There are exceptions for this, for instance large objects bigger than the blocksize but these can be handled separately.
The code to trap intra block pointer writes looks like the following:
xor sourcePointer, destPointer
or result, blockSizeMinus1
jnz codeToHandleIntraBlockPointers
As people can see, including the jump its only three instructions on the x86 (I think!!!)
This only has to be triggered when a member pointer of one class is set. Not for intermediate local variables.
Storing intra-block pointer writes
Pointers that are detected as being intra-block need to be stored for later analysis. What this document proposes, is to have a system wide array of pointers with as many elements in it as blocks. The size of this array would be determined by the following equation:
size of array = amount of system memory / size of block
Each element in the array corresponds to a block in memory. Each array element contains a list of pointers pointing to elements held in the corresponding block.
The address of the source pointer is added to the linked list pointed to by the array element that corresponds to the block that contains the destination pointer. The effect of this is each block now has a set of addresses of pointers pointing into it. Of course there can be duplicates, but the critical thing is this list is time ordered. Thats very important.
Now the elements in these lists do not get modified by the mutator after they are created. This means that a thread running in parrallel can scan these lists and do the following:
- Remove obsolete references
- Remove duplicates
This will trim the list down to the bare root set of a given block. The time taken to do the above is proportional to the size of the list which is directly proportional to the number of intra-block pointer writes. Essentially what we're doing is delaying the processing of the lists so we can process a longer list in one go. This increases the change of duplicates in the list and therefore can make the process a lot more efficient. We can also run the list scanning algorithms on different threads therefore processors and possibly schedule more at system idle time.
But how are duplicates in the list detected and obsolete references.
Firstly to detect duplicates. With modern architectures we generally cant locate an object across a machine word. This means for instance that on a 32 bit architecture which is 4 bytes the bottom 3 bits of all pointers will be zero. This could be used as an information store. When scanning the list the pointers can be marked. If a pointer is allready marked dont add it to the new list thats building.
Secondly what about obsolete references? This is simple, if the pointer points to some other block now, its obsolete.
So the algorithm so far is this. Run a paralled thread to the mutators to cut down the pointers into a certain block. This incoming pointer list for the block will keep growing so we can say as soon as a certain percentage of the list is processed all the mutators are halted. The next step is to process the remained part of the list for the block we are just about to garbage collect. Now contained in that list we should have a valid set of roots for the block. We can garbage collect the block and move all the reachable objects to the new heap thats growing. Fix up the roots to point to the new object locations and the old block is now ready to be recycled.
the more observant readers will have asked about intra-block cycles. The technique I use is to have two categories of reached objects:
- strongly reached
- weakly reached
The idea of strongly reached objects is that there was a proveable link to the object sometime during the last cycle. Weakly reached objects could either be junk or referenced. Strong reached objects are copied out to a new heap. Weakly reached objects can either be left of place or copied to a weakly reached heap. When we have no referenced from the strongly reached haep to anywhere else we know we can stop garbage collecting.
... more to come ...
Graphics framework
This is where the graphics framework requirements & specification will come.
Current project members:
- Valentin
- Levente
- Nathan
My current thoughts on the graphics framework is that the graphics driver is passed the basic hardware resources it needs. It cannot access any other hardware resources.
The driver needs to provide a list of supported video modes, resolutions and refresh rates. The driver might also provide infromation about the attached video display device. E.g. flat panel, resolution, make model refresh rate etc.
There needs to be a standard way to query the driver about the supported display modes. Either we have the display driver implementing an interface or have an abstract method on a base class.
The DisplayMode interface might have the following methods:
The above interface begs the question whether there should be two sub-interfaces, TextDisplayMode and GraphicsDisplayMode. Should the graphics driver export the two lists separately? Most graphics cards enter a text display mode by default I think. Some export their own special text display modes.
Coments from Valentin:
My Opinion is that we should pack this informations that the driver can send back into an external class called GraphichDriverInfo and that we should have 2 other interfaces called TextDisplayMode and GraphicsDisplayMode that extend DisplayMode interface. So the list of classes/interfaces(and there methods) should look like this:
Everyone's input on this is wellcomed.
Isolate proposal
Goal
Isolates are intended to seperate java programs from each other, in order to protect java programs from (intentional) errors in other programs.
Proposal (in concept)
I propose to make an Isolates implementation that is somewhere between full isolatation and full sharing. With the goal in mind, programs should be protected from each other, which means that they should not interfere each other in terms of resources, which are typically:
- Memory
- Threads
- Locks
This means that everything that can be used to interfere other programs on these items must somehow be protected. Everything else must be as shared as possible, in order to minimize resource usage.
Think can be achieved by isolating certain resources, and making serveral services aware of the fact that there are isolates. E.g. a network stack should be aware that network bandwidth is shared nicely across all users, in order to prevent a single program from eating away all network bandwitdh.
What is Isolated v.s. Shared
Isolated:
- Static variables
- Java class structures (Class, Field, Method)
- Class initialization
- Java threads (java.lang.Thread)
- Java object heaps
Shared:
- Static variable indexes (in statics table)
- Internal class structures (VmType, VmField, VmMethod)
- Compiled (native) code
- Internal thread structures (VmThread)
- OS services (drivers, filesystems, networking)
- System resources (memory, IRQ)
- Raw memory blocks (MemoryBlockManager)
Explaination:
Static variables in JNode are implemented in statics tables. The index (of a static variable) in this table must be constant across all isolates, otherwise the compiled code needs to retrieve the index on every static variable get/set which is very expensive. Havig said this, this does imply that statics table will become pretty large. This can be solved by implementing a cleanup strategy that frees indexes when they are no longer used.
For the rest, the seperation is made in terms of publicly accessible versus internal. E.g. a java program can synchronize on a Class instance, but since these are isolated, this will not block all other programs.
Isolated java heaps will have significant implications on the code of the shared services, so this will something to do in step 2.
Isolated java heaps
Isolating memory allocation will cause some problems that need to be dealed with.
Problems
When an object is allocated in one isolate, and this isolate is closed, the object is also removed. But what if this object is registered somewhere in another isolate?
Answer: A problem. Objects may not cross isolate bounderies.
JNode Installer proposal
- Name of the submitter:
- Valentin Chira
- Goal of the proposal:
- Unify the way modules are installed / maintained in JNode. By “module†one must understand any application, library, driver or plug-in.The installer repository must be also used to lunch installed applications.
- Functional description:
- The Installer should serve as a main administration tool for the installed modules and as a tool to be used to install new modules in JNode. One of the modules should be JNode itself. Each module definition must be a list of its sub-modules, own files, external library references (needed to run the module), security requirements, external installer, etc. The user must be able to interact with the installer through a “command lineâ€/â€graphical†interface and perform administrative operations like updating a module, installing new modules or removing a module. For ease of use the user must be able define “modules clusters†and aggregate more modules in a cluster. For example one of this clusters can be called “system†and be JNode itself. One important function that the installer must support is version administration for modules. The installer must support the administration of modules at the level of version so that multiple version of the same module can be installed. The first “use case†for the installer is JNode installation itself. The JNode installation should consist of installing a minimal JNode version on the HDD edit the “system†cluster modules list and than call the installer to update/install the modules from the list, ex: “installer –u systemâ€.
- Architecture
-
The installer module should be based on a standard Java technology. This is why I believe we should use JNLP which offers a standard way to install modules. The installer should be a JNLP client that has a cache/repository attached. The Installer should cache the JNLP files for all installed modules and also keep an index file for the installed modules. I propose that this index file to be an xml file called “index.xmlâ€. The storage representation should look like this:
- /jnode/installer/repository/
- .../app1/app1.jnlp
- .../app1/submodule1.jnlp
- .../app2/app2.jnlp
- .../app2_ver_0.01/app2.jnlp
- .../lib1/lib1.jnlp
- .../driver1/driver1.jnlp
- /jnode/installer/index.xml
The index.xml file will contains at least one entry for each installed module and all created clusters. This is should look pretty much like a database(maybe we could use here a small xml database engine). The index file is loaded at first use of the installer and should be cached in memory. The index.xml structure should be something like this:
- module>
- name="app1"
- version=0.01
- cluster="system"
- JNLPfile="app1.jnlp"
- updateURL="www.jnode.org/autoupdate/system/app1.jnlp"
- /module>
- cluster>
- name="drivers"
- cluster="system"
- /cluster>
- cluster>
- name="system"
- /cluster>
The process of installing a new application should be no more than downloading the jnlp file, copy the files described there and than modify the index.xml file to add the new installed application. Here we could have problems if another application with the same name is installed. In this case I think we should just ask the user for an alternative name. Maybe in the index.xml we could store not just 1 name but 2: originalname="app1" and name="editor". In this way one could install applications with the same jnlp name. A trickier problem is version handling.
The most important operation that the installer must support is updating the packages which are already installed. This operation must care for all dependant packages and should start by downloading the new jnlp file into a temp folder. Let’s assume the following scenario:
The user runs in console the following command:
"/> installer –u system"
What the installer should do first is find what is associated with name system. Lets say that system is a cluster of modules than the installer should update all modules from “system†cluster. This means finding all the modules that belong to this cluster or sub-clusters read their updateURL entry and download the new JNLP files and execute them. In the process of installation of a new version the installer must check if the external resources of the new version have the version described in the JNLP file and if they don’t than this resources must be updated as well. The update of resources must be done only if no other module uses the current version of the resource. In our example lets say that module service-manager has a new version which needs ant version 1.6 but locally we have ant 1.5 installed than ant must be updated as well if no other modules use ant 1.5. If ant 1.5 is still used than the new version of ant must be installed separately and the old version kept. - References:
- Sun JNLP specification
- Portage application developed for Gentoo Linux distribution
Addendums
markhale: Details on use of JNLP files.
Three types of modules have been identified; applications/applets, libraries and system level plugins (includes drivers). The purpose of this note is to detail how each type of module is described by a JNLP file.
- Applications/applets
- Well-known description using application-desc or applet-desc.
- Libraries
- Using component-desc.
- System plugins
- Propose the introduction of jnode:plugin-desc. To do: give a mapping of existing plugin xml to jnlp xml. import->part,export->package???
To allow for finer-grain control of security, introduce jnode:permission child element of jnlp security element.
jnode:permission will have the following required attributes: class, name, actions.
JNode System-file Tree Structure
It is time for us to start thinking about how JNode should run from a normal harddisk based system, how it should be installed and maintained.
An essential part of this, is how and where system files should be stored, and what system files are. This page answers the question of what system files are and proposes a tree structure for system files to be stored.
What are system files
In JNode there are a few different types of system files. These are:
- Kernel image, (jnodesys.gz) which contain the nano-kernel, the system plugins and the system classes.
- Initial jars, (e.g. default.jgz) which contain the plugins needed to start the system.
- Plugins, which contain services (drivers, apps, ...) and are loaded on demand.
- Configuration data, which contain configuration data specific to the device it is installed on.
- Bootloader files, (stage2, menu.lst) used by Grub to boot the system.
Tree structure
In JNode system files should be placed in a container in a structure that is "well known".
A container can be a filesystem, but can also be some kind of database. See the next paragraph for a discussion on this.
The proposed tree is as follows:
| /jnode | The root of the container |
| /jnode/system | Contains kernel and the initial jars |
| /jnode/plugins | Contains the plugins |
| /jnode/boot | Contains the bootloader files |
| /jnode/config | Contains the configuration data |
System file container
Traditionally the system files are stored in a directory on a "root" filesystem. This filesystem is identified by a parameter, or some flag in a partition table.
This method is easy, because all normal filesystem tools can be used on them, but makes it harder to protect these files against virusses, ignorent users etc. Also this method limits the system files to being harddisk based. (E.g. look at the trouble Linux had to have an NFS root filesystem).
For these reasons, I propose a more generic method, that of an abstract container interface for system file access. This interface can have implementation ranging from a single file based container to a network loader. The essential part is that the actual implementation is hidden from the part of JNode that uses it (either to load files, or to install them).
This is all for now, please comment on this proposal.
Ewout
Networking proposals
This is a branch for the proposals of the networking subsystem
A new networking framework
Networking framework
The goals of this proposal:
- Flexibility, more capabilities
- Simplicity, better Object-Oriented design
The following are the 3 basic types of entities within this framework:
- Network devices
- Network filters
- Applications.
The network devices are the device drivers of the Network interfaces or virtual network drivers (like the local loopback). We assume that a device driver like that takes a packet stored in a memory buffer and write it on the media (wire, air or anything else). Also it receives a packet from the media and writes it to a memory buffer. The device drivers that do some job of the networking system, such as checksum calculation or crypto work, may be treated also as Network filters (they will be discussed later).
At the opposite hand are the applications. This is any software that creates packets and injects them, or receives a packet from the networking subsystem. For example: a ping command, or dns server software, and also the java SocketImpl system.
Both Network device drivers and applications are the endpoints of this model. From them the packets are coming in and out of the networking subsystem of the OS. Between them we have the Filters.
The filters take packets from any component and forward them to other components. A subcategory of them, are the protocol stacks. The filters are the components that are used to transform the packets or do other things with these packets. For example a TCP/IP stack is a filter that parses the incoming byte arrays (RawPacket from the device driver) to TCP/IP packets, or encapsulates data into TCP/IP packets to be sent later over another protocol. There is more that the TCP/IP stack will do internally, but it’s a matter of the TCP/IP stack implementation and not of this framework proposal.
These filters have one or more PacketStreams. Most components may have two packet streams. Any packet stream implements two interfaces, the PacketListener and the PacketFeeder. Any PacketListener may be registered to a feeder to receive packets from him. This way we can have Chains of packet streams, some of them may split (?)*. Also a filter may be just a PacketFeeder or PacketListener. For example a component that captures packets directly to the filesystem, a counter for some specific packets, a traffic generator, etc (but they may not be treated as endpoints).
For performance reasons we can use a “listening under criteria†system. And only when these criteria are matched the feeder will send the packet to this listener. We can have an interface ListenerCriteria with a simple listener specific method that reads some bytes or anything else from the incoming packet and return true or false. This method will be called from the packet feeder, before he sends the packet to the listener. For example an IPListenerCriteria will check the ethertype bytes if the packet feeder is EthernetLayer. Or another ListenerCriteria implementer may check the class of a packet to see if it is instance of the ICMPPacket. Listening under criteria will be a way to filter packets that will be passed from stream to stream.
The PacketFeeder’s will have a registry, where they store the currently registered listeners to them. For this registry I suggest to use a List of bindings, where every binding of this list will have as key a PacketCriteria type instance and as value a list of the PacketListeners that are listening under these criteria.
For performance reasons, a packet feeder may have two or more different registries of listeners, one for the high priority listeners and one for the others or one registry for the protocol to protocol submission and one for the others (and if they exist).
To avoid deadlocks between components and performance degradation, when a feeder passes a packet to a listener, the listener may use incoming queue and have its own thread to handle the packet. Except if the packet handling that he would do is something very quick.
Another issue, is how all this relations between the components will be managed. A command or a set of commands will be useful. This is a part of Ifconfig mainly.
The result of all these will be a web of networking components, where everyone can communicate to everyone. Think the possibilities, I have found many already.
This is an abstract of what I am thinking. The details is better to be discussed here.
Pavlos Georgiadis
Packet representation
Packet representation
The goal of this proposal is mainly to speed up the packet handling and to provide the developers a simpler and more Object Oriented packet representation. It aims to remove the current SocketBuffer and replace it with Packets.
Currently the packets are represented with the SocketBuffer class. The SocketBuffer is something like a dynamic buffer (to be more accurate it is more like a list of dynamic buffers). When a program wants to send a network packet, it creates the protocol headers, and then the headers are inserted in this buffer list with the packet payload (if there is a payload). Finally the NIC driver copies all the bytes of the packet into another fixed array to be used from the driver.
When we send a packet we move all the packet data 2 times (from the headers to the SocketBuffer and from it to the final fixed array). When we receive a packet, the SocketBuffer acts like a fixed array, which provides us with some useful methods to read data from him.
What I suggest is to represent the packets as…Packets. All the protocol packets are the same thing. They have a header and a payload (some of them have a tail too). Every packet is able to know its size and how to handle its data (including the payload).
So let’s say we have the interface Packet.
What we need from the Packet implementers:
- Set and Get methods for the data of the packets (class specific and wont be in the Packet interface)
- A way to store the data in an object and to have a method that will return the entire packet as a byte[] (when we send the packet).
- Methods that will parse a byte array to create the Packet object (when we receive a packet).
Any packet is represented with a class that implements the Packet interface. For example IPv4Packet, ICMPPacket, TCPPacket etc. Every component of the networking can access the data of this packet with the appropriate set and get methods (If a program uses a packet knows it’s specific assessors).
To accomplish the second and the third we need the following methods for the interface Packet:
public void getData(byte[] b);
public void getData(byte[] b, int offset);
public void getSize();
The getData(byte[] b) writes the packet in the given byte array. If the length of this array is not enough we can throw an exception. The getData(byte[] b, int offset) writes a packet to the array b, starting from the offset position. The getSize method will return the length of this packet, including the length of its payload.
These methods will be called mainly from the network drivers. This is the point where the packet is converted from object to a memory buffer and vice versa.
When the Ethernet protocol sends a packet to the driver the driver will call the getSize() of the Ethernet packet to determine how big will be the array that will store the entire packet. The Ethernet packet getSize() method will return for example 14+payload.getSize(). Remember that the payload is also a packet, let’s say an IP packet that may return for example 20+payload.getSize(). As the driver has determine the length of the entire packet, it will create the memory buffer b and it will call the getData(byte[] b) to the Ethernet packet, which will write the first 14 bytes and also it will internally call payload.getData(b, 14). This way we move the data only once, from the objects to the final byte array.
A common class that implements the Packet interface is the RawPacket, which is a packet that maps a byte array, or a portion of this array as packet.
The Raw packet will be mainly used:
- To store the data payload of a packet (for example the data payload of a TCP packet)
- To map a received packet before it will be parsed from the networking components.
A practical example for the second:
When a packet is received from a NIC, the driver will create a RawPacket with the array that stores the currently received frame. Later this RawPacket will be send for example to the Ethernet protocol, which will parse the first 14 bytes to its attributes and create another (or modify the same) RawPacket that will map the same byte[] from the position 15 to the end. This RawPacket will be the payload of this Ethernet packet, that later will be send to the IPv4 stack for example and so on.
Pavlos Georgiadis
FAQ
Are there any plans to support GNU Classpath?
GNU classpath is currently used. There are however some minor differences.
It is intended that Classpath is used out of the box somewhere in the future. In the mean time, classpath is part of the JNode source repository and is synced on a somewhat regular based with the latest version from classpath.org.
Edited by Fabien D :
Since it is open sourced, we are moving to openjdk (instead of using GNU Classpath).
Are you using openjdk ?
Since it is open sourced, we are moving to openjdk (instead of using GNU Classpath).
At the time I am writing this article, we have misc sources from both GNU Classpath, openjdk and icedtea(the parts that are not free in jdk will be replaced by free parts from GNU world)
How do I configure the network in JNode?
The network can be configured with dynamic IP address or with a fixed IP address.
Note : To find the name of your network card, just type "ifconfig" and you will get a list of available devices.
Configuring the "loopback" interface
You need to configure the loopback interface for the DNS setup performed by the dhcp to work.
- Run ifconfig as follows:
ifconfig loopback 127.0.0.1 255.255.255.255
Configuring JNode with a dynamic address
- Configure "loopback" as above.
- Run the dhcp command followed by the name of the network card. For example:
dhcp eth-pci(0,17,0) - If dhcp fails with an exception that talks about a timeout, try the command again.
Configuring JNode with a fixed IP address
- Use the ifconfig command to set your desired IP address. For example:
ifconfig eth-pci(0,17,0) 192.168.0.10 - Now, use the route command. For example:
route add 192.168.0.1 eth-pci(0,17,0)
To read more about the commands and their options see the user docs.
How to join the development team
The answer is on this page.
What is the minimal required hardware?
To run JNode on and X86 PC, you must have at least the following hardware.
Pentium processor
256Mb RAM
To run it a bit more interesting, the following hardware is recommended (or better).
Pentium 3 processor
512Mb RAM
32-bit graphics card
Will XYZ run on JNode?
People often want to know if their favorite Java-based application or library runs on JNode.
The short answer is usually: "We don't know; why don't you give it a try?".
The long answer is that it depends on the nature of the application. Here are some guidelines:
- Non-GUI based applications that are pure Java and that use only J2SE libraries have a chance of working right now.
- Applications that use AWT/Swing or that stress garbage collection, multi-threading and the security model may have problems right now. JNode's deficiencies are being addressed; please feel free to help.
- If the application has (or depends on) C/C++ libraries, then it will not work unless the libraries are recoded in Java.
- If the application relies on external (non Java) programs then it will not work unless
those programs can be coded in Java and ported to JNode.
Papers & presentations
The page contains references to papers and presentations written about JNode.
If you're paper/presentation is not yet listed here, contact the admin.
Papers:
- Jini on the JNode Java OS by Sebastian Lohmeier
Presentations:
- "Why Java is practical for modern operating systems", by Ewout Prangsma at Libre Software meeting 2005.
References
- JOEQ another Java VM
- Classpath, an open source Java library implementation
- Classpath vm integration guide
- Zaval LwVCL graphics component library
- Jikes Research VM by IBM (Jikes RVM)
- Memory Manager Toolkit (MMTk, part of Jikes RVM)
- JX Operating System
- JanosVM
Grub boot loader
File systems
Ext2
- A Non-Technical Look Inside the EXT2 File System
- The superblock
- Internal Layout
- John's ext2 spec
- The Second Extended Filesystem
- ext2 spec
- Understanding the Linux kernel - chapter 17
BeFS
HFS/HFS+/HFSX
Graphic specifications
General Graphics standards
- VESA Bios Extension (VBE) 3 specifications (broken link : the file is now attached)
- Vesa Generalized Timing Formula (VESA-1999-9) implemented in a spread sheet
Graphics Card Specifications
Relevant JSRs
Specification sites
- Operating systems
- Hardware
- Guide to ATA/ATAPI documentation
- Microsoft WDEV
- Microsoft ACPI/Power management (hot plug&play, ...)
- El Torito Bootable CD-ROM Format Specification Version 1.0 (January 25, 1995)
- Fonts
- TrueType Reference Manual (TTF)
- TrueType typography (TTF)
- Font metrics and glyph (explanation of terms)
- Compiler
- Evolution of a Java Just-in-Time Compiler for IA-32 Platforms describing the idea behind JNode's l1a compiler.
Research
The page contains references to research done with and around JNode.
If you're research topic is not yet listed here, contact the admin.
- Jamaica project at the University of Manchester